首页
AI 平台
AI 推理服务
AI Infra
AI 应用实践
AI RCA
平台工程
Kubernetes
云原生
容器平台
交付平台
微服务治理
网关与流量治理
服务网格
可观测性
链路追踪
日志收集
指标监控
运维与Linux
运维
Linux
大数据
散宜生的个人博客
累计撰写
238
篇文章
累计创建
148
个标签
累计收到
0
条评论
栏目
首页
AI 平台
AI 推理服务
AI Infra
AI 应用实践
AI RCA
平台工程
Kubernetes
云原生
容器平台
交付平台
微服务治理
网关与流量治理
服务网格
可观测性
链路追踪
日志收集
指标监控
运维与Linux
运维
Linux
大数据
目 录
CONTENT
以下是
vLLM
相关的文章
2025-10-12
vLLM 和 SGLang 到底怎么选
当一套大模型私有化部署路线已经从环境准备、K8S 底座、vLLM 实战和 SGLang 实战全部走通之后,真正绕不开的问题就只剩下一个:vLLM 和 SGLang 到底该怎么选。本文不再重复安装步骤,而是从目标、场景、团队阶段、复杂度和运维成本五个角度,把这两个框架的差异和选型逻辑讲清楚。
2025-10-12
15
0
0
AI 推理服务
2025-10-01
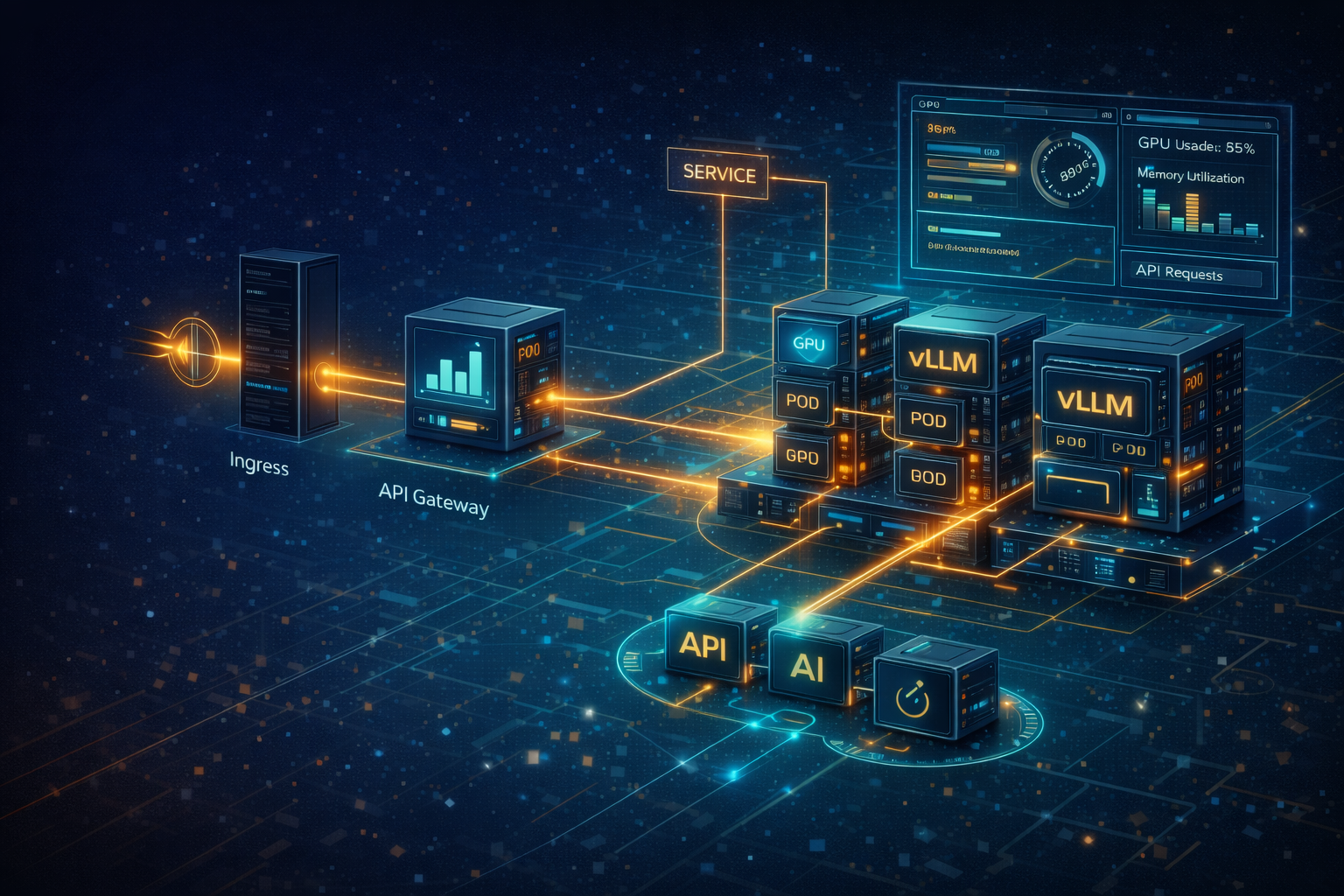
vLLM 上 K8S:服务部署、对外暴露、监控与验证
当 vLLM 已经能在单机上通过本地或 Docker 方式稳定提供 API 后,下一步自然就是把它放进 K8S,变成团队可以共享、扩展和观测的正式推理服务。本文按实战顺序完成这条链路:部署 NVIDIA Device Plugin、准备模型存储、发布 vLLM 工作负载、通过 Service 和 Gateway 对外暴露,并补上 GPU 与服务层监控。
2025-10-01
12
0
0
AI 推理服务
2025-09-28
vLLM 私有化部署实战:本地部署、Docker 部署、接口验证
当你已经用 Ollama 跑通过一条可交互体验链路之后,下一步通常就该进入更正式的推理服务路线。对很多团队来说,vLLM 正是这一步的自然选择。本文把 vLLM 的两条典型起步路径拆开讲清楚:本地 Python/Conda 部署和 Docker 容器部署,并在关键步骤补充命令、输出和 OpenAI 兼容接口验证方法。
2025-09-28
5
0
0
AI 推理服务
2025-09-14
大模型推理环境准备实战:GPU、驱动、CUDA、容器运行时
大模型私有化部署最容易踩的坑,不是模型本身,而是底层运行环境没有理顺。GPU 能否被系统识别、驱动和 CUDA 是否匹配、PyTorch 能否正确调用显卡、容器运行时是否完成 GPU 透传,这几层只要有一层没打通,后面的 vLLM、SGLang、Ollama 和 K8S 部署都会反复出问题。本文从实战角度把这些关系一次讲清楚。
2025-09-14
19
0
0
AI Infra
2025-09-10
本地、Docker、K8S:大模型私有化部署路线怎么选
大模型私有化部署最容易踩的坑,不是某个命令执行失败,而是一开始就把路线选复杂了。这篇文章不讲具体安装步骤,而是先把路线拆清楚:本地、Docker、K8S 分别适合什么阶段,Ollama、vLLM、SGLang 又该怎么搭配,帮助你少走弯路地完成从验证到服务化的演进。
2025-09-10
4
0
0
AI Infra