


Impala 介绍
- Impala 简介
Impala由Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。是CDH平台首选的PB级大数据实时查询分析引擎。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点就是基于内存处理数据,查询速度快。
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。
Impala与Hive在Hadoop中的关系下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。 - Impala 架构
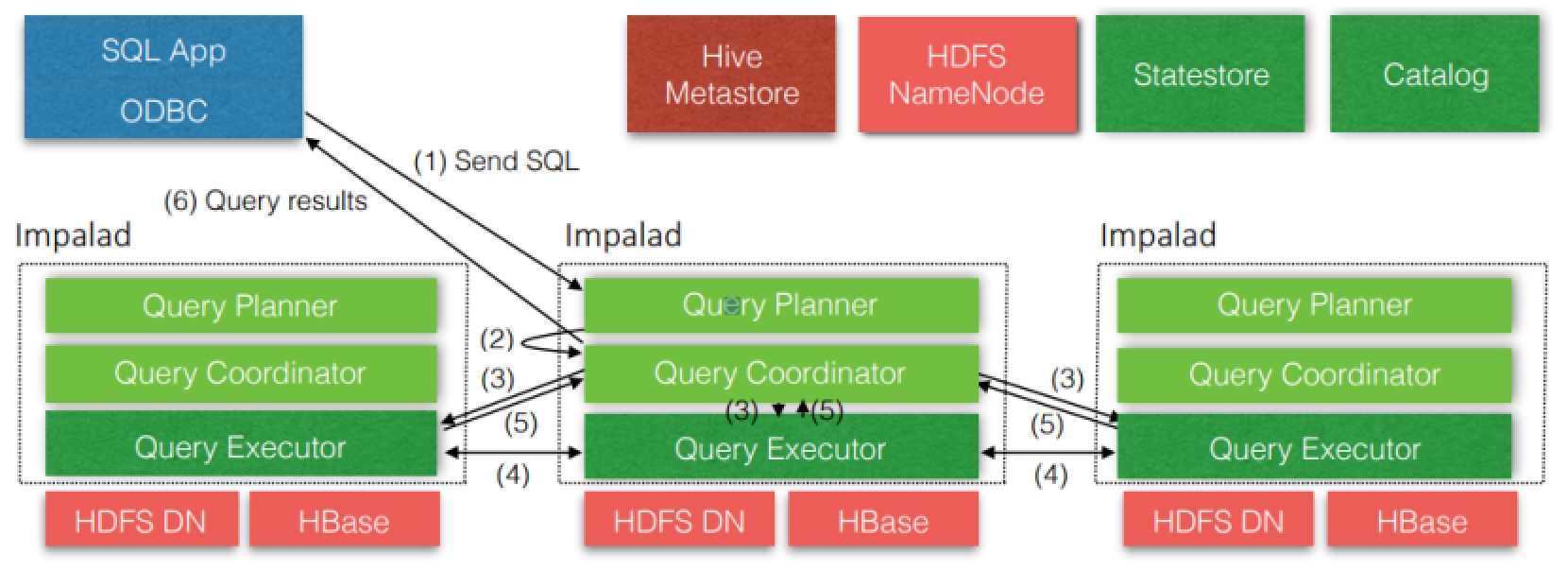
Impala 主要由 Impalad、State Store、Catalog 和 CLI 组成:
- Impalad:
与 DataNode 运行在同一节点上,由 Impalad 进程表示,它接收客户端的查询请求(接收查询请求的Impalad为Coordinator,Coordinator通过 JNI [java native interface]调用Java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它 Impalad 进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给 Coordinator,由Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
每个impalad实例会接收、规划并调节来自ODBC或Impala Shell等客户端的查询。每个impalad实例会充当一个Worker,处理由其它impalad实例分发出来的查询片段(query fragments)。客户端可以随便连接到任意一个impalad实例,被连接的impalad实例将充当本次查询的协调者(Ordinator),将查询分发给集群内的其它impalad实例进行并行计算。当所有计算完毕时,其它各个impalad实例将会把各自的计算结果发送给充当 Ordinator的impalad实例,由这个Ordinator实例把结果返回给客户端。每个impalad进程可以处理多个并发请求。 - Impala State Store:
负责Quary的调度及跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后,因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据。 - Catalog:
当Impala集群启动后,负责从Hive MetaStore中获取元数据信息,放到impala自己的catalog中。Catalog会与StateStore通信,将原数据信息通过StateStore广播到每个Impalad节点。同时当Impala客户端在某个Impalad中创建表后,Impalad也会将建表的原数据信息通过State Store通知给各个Impalad节点和Catalog,由Catalog同步到Hive的元数据中。注意Hive中创建表产生的原数据信息,不能同步到catalog中,需要手动执行命令同步。
- CLI(Impala Shell):
命令行客户端,提供给用户查询使用的命令行工具。
- Impala 的优势:
- 基于内存进行计算,能够对PB级数据进行交互式实时查询、分析。
不需要把中间结果写入磁盘,省掉了大量的I/O开销。最大限度的使用内存,中间结果不写磁盘,Impalad之间通过网络以stream的方式传递数据。 - 无需转换为MR,直接读取 HDFS 数据。
省掉了MR作业启动的开销,Impala直接通过相应的服务进程来进行作业调度,速度快。 - C++编写,LLVM统一编译运行。
LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time)。使用C++实现,做了很多针对性的硬件优化。 - 兼容HiveSQL,可对 Hive 数据直接分析。
- 支持Data Local
Impala支持Data Locality的I/O调度机制,尽可能的将数据和计算分配在同一台机器上执行,减少网络开销。 - 支持列式存储
- 支持 JDBC/ODBC 远程访问
- 基于内存进行计算,能够对PB级数据进行交互式实时查询、分析。
- Impala 的劣势:
- 对内存的依赖大、要求高
- 完全依赖 Hive,不支持 Hive 的 UDF 和 UDAF 函数,不支持查询期的容错
- 分区超过 1w 性能严重下降
- 稳定性不如hive
- Impala 与 Hive 的异同:
- 相同点:
impala与Hive使用相同的元数据,都支持将数据存储在HDFS和Hbase中,都是对SQL进行词法分析生成执行计划。 - 不同点:
- 执行计划:
Hive: 依赖与MapReduce执行框架,执行计划分为map->shuffle->reduce->map->shuffle->reduce…由于中间有很多次shuffle,SQL执行时间长。
Impala: 执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad中执行查询,而不需要转换成MapReduce模式处理,保证impala有更好的并发性和避免不必要的中间sort和shuffle。 - 数据流:
Hive: 采用推的方式,每个计算节点计算完成之后将数据主动退给后续节点。
Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,此方式可以将数据流式的返回给客户端,只要有一条数据处理完成,就可以立即被展示出来,不需要等待全部数据处理完成,更符合sql交互式查询。 - 内存使用:
Hive:在执行过程中如果内存放不下数据,则会使用磁盘,保证SQL能顺序执行完成,每一轮Map-Reduce执行结束后,中间结果也会落地磁盘。
Impala: 在遇到内存放不下数据时,就会报错。这使impala处理数据有一定的局限性,最好与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程中不会有写磁盘操作(insert除外)。 - 调度:
Hive: Hive调度依赖于Hadoop的调度策略。
Impala: 调度由Impala自己完成,会尽量将处理数据的进程靠近数据本身所在的物理机器。 - 容错:
Hive: 依赖于Hadoop的容错能力。
Impala: 整体来看,Impala容错一般,用户可以向任意一台impalad提交SQL查询。如果一个Impalad失效,在当前Impala上执行的所有SQL查询将失败,但是用户可以重新提交查询由其他的Impalad代替执行,不影响服务。在查询过程中,没有容错逻辑,如果执行过程中发生故障,则直接返回错误。对于Impala中的State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能在更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致SQL执行失败。 - 适用方面:
Hive:复杂的批处理查询任务,数据转换任务。
Impala:实时数据分析,因为不支持UDF,对处理复杂的问题分析有局限性,与Hive配合使用,对Hive的结果数据集进行实时分析。
- 执行计划:
- 相同点:
Impala 安装
- 选择集群,添加服务
- 添加服务向导
在弹出的窗口中选择Impala,点击“继续”:
角色按照默认配置即可,点击“继续”:
选择impala的数据目录,默认即可,点击“继续”->“完成”,完成impala的安装:
Impala 使用
在集群主页上,启动impala。
-
测试 Hive&Impala 的速度
首先在cm-a1中切换hdfs用户,默认CM在创建hdfs用户时,禁用了使用hdfs用户进行ssh登录,这里需要执行命令(建议所有节点都执行):
# -s 修改用户登入后所使用的shell,/bin/bash 可以使用 ssh 登录 usermod -s /bin/bash hdfs在cm-a1节点进入hive的cli模式,在之前hue的使用中,给Hive中插入过表“my_hive_table”,执行sql语句查看在hive中执行的速度:
[root@cm-a1 ~]# su - hdfs [hdfs@cm-a1 ~]$ hive hive> show tables; OK my_hive_table Time taken: 1.388 seconds, Fetched: 1 row(s) hive> select count(*) from my_hive_table; Query ID = hdfs_20201219230917_f80fddf0-4cd5-4312-9b5d-eee348873025 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> 20/12/19 23:09:18 INFO client.RMProxy: Connecting to ResourceManager at cm-s1/192.168.0.50:8032 20/12/19 23:09:19 INFO client.RMProxy: Connecting to ResourceManager at cm-s1/192.168.0.50:8032 Starting Job = job_1608368375807_0001, Tracking URL = http://cm-s1:8088/proxy/application_1608368375807_0001/ Kill Command = /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hadoop/bin/hadoop job -kill job_1608368375807_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2020-12-19 23:09:29,298 Stage-1 map = 0%, reduce = 0% 2020-12-19 23:09:36,562 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.11 sec 2020-12-19 23:09:41,719 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.43 sec MapReduce Total cumulative CPU time: 4 seconds 430 msec Ended Job = job_1608368375807_0001 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.43 sec HDFS Read: 8206 HDFS Write: 101 HDFS EC Read: 0 SUCCESS Total MapReduce CPU Time Spent: 4 seconds 430 msec OK 4 Time taken: 24.865 seconds, Fetched: 1 row(s)其次,在cm-a2节点上执行impala-shell,执行相同的语句查看执行时长:
[root@cm-a2 ~]# impala-shell [cm-a2:21000] default> show tables; Query: show tables +---------------+ | name | +---------------+ | my_hive_table | +---------------+ Fetched 1 row(s) in 0.20s [cm-a2:21000] default> select count(*) from my_hive_table; Query: select count(*) from my_hive_table Query submitted at: 2020-12-19 23:13:20 (Coordinator: http://cm-a2:25000) Query progress can be monitored at: http://cm-a2:25000/query_plan?query_id=c54e845d765ee26b:170694bb00000000 +----------+ | count(*) | +----------+ | 4 | +----------+ Fetched 1 row(s) in 4.35s [cm-a2:21000] default> select count(*) from my_hive_table; Query: select count(*) from my_hive_table Query submitted at: 2020-12-19 23:15:31 (Coordinator: http://cm-a2:25000) Query progress can be monitored at: http://cm-a2:25000/query_plan?query_id=3942cc9232942583:fd88131300000000 +----------+ | count(*) | +----------+ | 4 | +----------+ Fetched 1 row(s) in 0.12s -
测试 impala 创建表同步元数据
在impala中创建一张表,查看是否元数据会同步到Hive的MetaStore,在impala-shell中执行建表语句:[cm-a2:21000] default> create table impala_table (id int,name string,score int) row format delimited fields terminated by '\t'; Query: create table impala_table (id int,name string,score int) row format delimited fields terminated by '\t' +-------------------------+ | summary | +-------------------------+ | Table has been created. | +-------------------------+ Fetched 1 row(s) in 0.41s同时,在cm-a1节点的Hive客户端查看是否有表“impala_table”,发现在 impala 中创建的表元数据在Hive中立即可以查询到。
hive> show tables; OK impala_table my_hive_table Time taken: 0.222 seconds, Fetched: 2 row(s) -
测试 Hive 创建表不同步元数据
在cm-a1节点的Hive中创建一张表,执行命令如下,在 impala 中看不到对应的表信息,需要手动更新元数据才可以。hive> create table my_hive_table1 (id int,name string) row format delimited fields terminated by '\t'; OK Time taken: 0.177 seconds在cm-a2节点查询 impala-shell,执行命令如下:
[cm-a2:21000] default> show tables; Query: show tables +---------------+ | name | +---------------+ | impala_table | | my_hive_table | +---------------+ Fetched 2 row(s) in 0.01s如果需要 impala 同步元数据信息,可以在 cm-a2 中 impala-shell 中执行
invalidate metadata命令:[cm-a2:21000] default> invalidate metadata; Query: invalidate metadata Query submitted at: 2020-12-19 23:27:22 (Coordinator: http://cm-a2:25000) Query progress can be monitored at: http://cm-a2:25000/query_plan?query_id=224a19b6b01245a9:e40cd10400000000 Fetched 0 row(s) in 4.10s [cm-a2:21000] default> show tables; Query: show tables +----------------+ | name | +----------------+ | impala_table | | my_hive_table | | my_hive_table1 | +----------------+ Fetched 3 row(s) in 0.01s -
impala shell命令
一般命令: -h(--help) 帮助 -v(--version) 查询版本信息 -V(--verbose) 启用详细输出 显示详细时间,显示执行信息。 --quiet 关闭详细输出 -p 显示执行计划 -i(--impalad=hostname) 指定连接主机 格式hostname:port 默认端口21000 -q(--query=query) 从命令行执行查询,不进入 impala-shell -d(--database=default-db) 指定数据库 -B(--delimited) 去格式化输出 --output_delimiter=character 指定分隔符,在-B指定情况下使用 将查询结果写往外部文件,或者输出时,指定输出字段间的分割符号。 例如: impala-shell -f xx.sql -c --print_header --output_delimiter="#" --print_header 打印列名 将查询结果写往外部文件时可以指定打印列名。 例如:impala-shell -f xx.sql -B -c --print_header -f(--query_file=query_file) 执行查询文件,以分号分割 -o(--output_file filename) 结果输出到指定文件 当前就是将1标准输出输出到文件 -c 查询执行失败时继续执行 举例:impala-shell -B -f xx.sql -c 1>out.txt,可以将结果输出到文件中,同时有错误直接跳过。 -k(--kerberos) 使用 kerberos 安全加密方式运行 impala-shell -l 启用 LDAP 认证 -u 启用 LDAP 时,指定用户名 特殊用法: help 在 impala-shell 中查看帮助 connect 连接主机,默认端口 21000 refresh 增量刷新元数据库 invalidate metadata 全量刷新元数据库 explain 显示查询执行计划、步骤信息 例如:explain select * from my_hive_table; set explain_level 设置显示级别(0,1,2,3),默认为1 set explain_level = 3; explain select * from my_hive_table; 级别越小,内容越精简,级别越大,内容越多。 shell 不退出 impala-shell 执行Linux命令 例如:shell cat ./xx.sql; profile (查询完成后执行)查询最近一次查询的底层信息 -
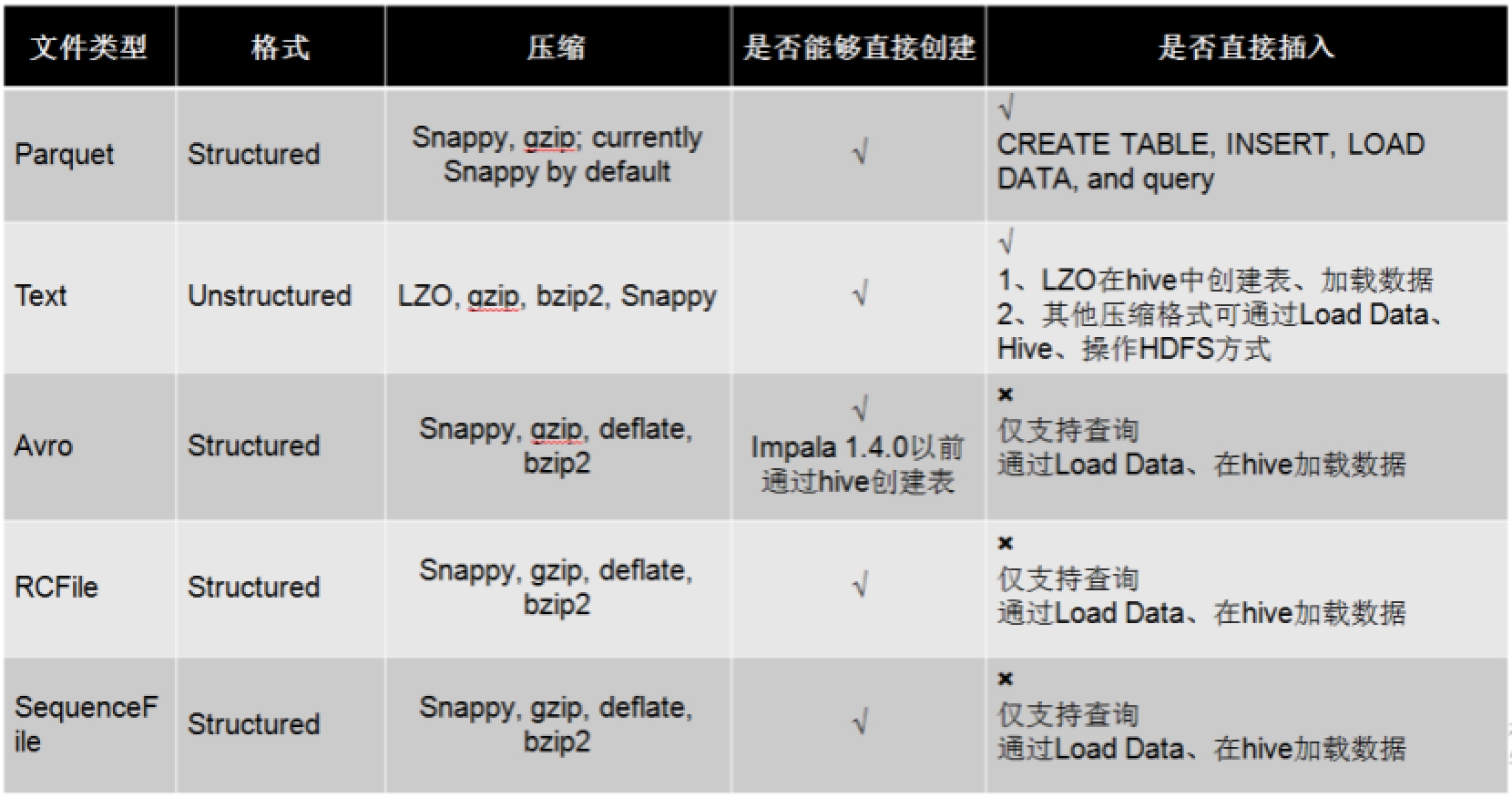
Impala 存储和压缩方式

评论区