


这是“微服务治理与平台化演进”系列的第二篇。
第一篇解决的是“服务怎么跑、服务在哪里被发现”,这一篇继续回答:这些被治理过的微服务,最终应该运行在一个什么样的平台之上。
摘要
这次 ACK 改造表面上看,是把原来运行在 ECS 上的微服务迁移到 Kubernetes;但如果只把它理解成一次“容器化搬迁”,意义其实被低估了。真正发生变化的,不是 Java 进程从主机搬进了 Pod,而是微服务终于拥有了一套平台化的运行时承载模型。本文会从运维实践和架构演进两个角度,复盘旧的固定部署模式为什么越来越吃力,ACK 在这里到底承接了哪些平台能力,以及它如何与 Nacos、APISIX、可观测和交付体系共同构成一条连续的微服务平台化演进路径。
系列导航
- 微服务治理:从 Git 托管 YAML 到 Nacos
- 容器平台:ACK 微服务容器平台建设
- 网关与流量治理:APISIX 与蓝绿灰度发布
- 可观测平台:指标、日志、链路三层建设
- 交付平台:从 Jenkins 到 GitOps
- AIOps / AI RCA:从可观测到智能故障分析
0. 导语:这不是把应用放进容器,而是把微服务放进平台
很多团队回顾容器化改造时,最容易把重点落在 Dockerfile、镜像构建、Deployment 编排、Ingress 暴露这些技术动作上。
这些内容当然重要,但如果把 ACK 改造理解成“把 Java 应用从 ECS 搬进 Pod”,其实很容易低估这件事真正的价值。
因为对微服务来说,真正困难的从来不是“能不能跑起来”,而是:
- 能不能稳定地跑
- 能不能持续地发
- 能不能快速地扩
- 能不能在故障发生时可控地回
- 能不能让环境边界、发布边界和服务边界同时成立
从这个角度看,容器化真正改变的,从来不是部署介质,而是运行时承载模型。
在我们这次改造之前,微服务虽然已经跑在云上,但它的运行方式仍然是典型的“主机时代”思路:固定的 ECS、固定的目录、固定的端口、固定的启动命令,再配合 Jenkins 和 Ansible 完成构建发布。这样的模式在服务规模还不大时完全可以工作,但随着微服务数量增加、发布频率提升、环境数量增多,它的问题会越来越明显。
而 ACK 在这里真正承接的,也不是“把应用装进容器”这么简单。它承接的是一整套原来缺失的平台能力:
- 工作负载标准化
- 健康检查与故障转移
- 先启后停的滚动发布
- 资源隔离与资源声明
- 弹性扩缩容
- 原生回滚
- 可观测能力接入
- 入口层与服务层协同治理
所以如果要给这次改造下一个更准确的定义,我更愿意这样说:
从 ECS 到 ACK,真正变化的不是运行位置,而是微服务终于拥有了一套平台化的运行时承载模型。
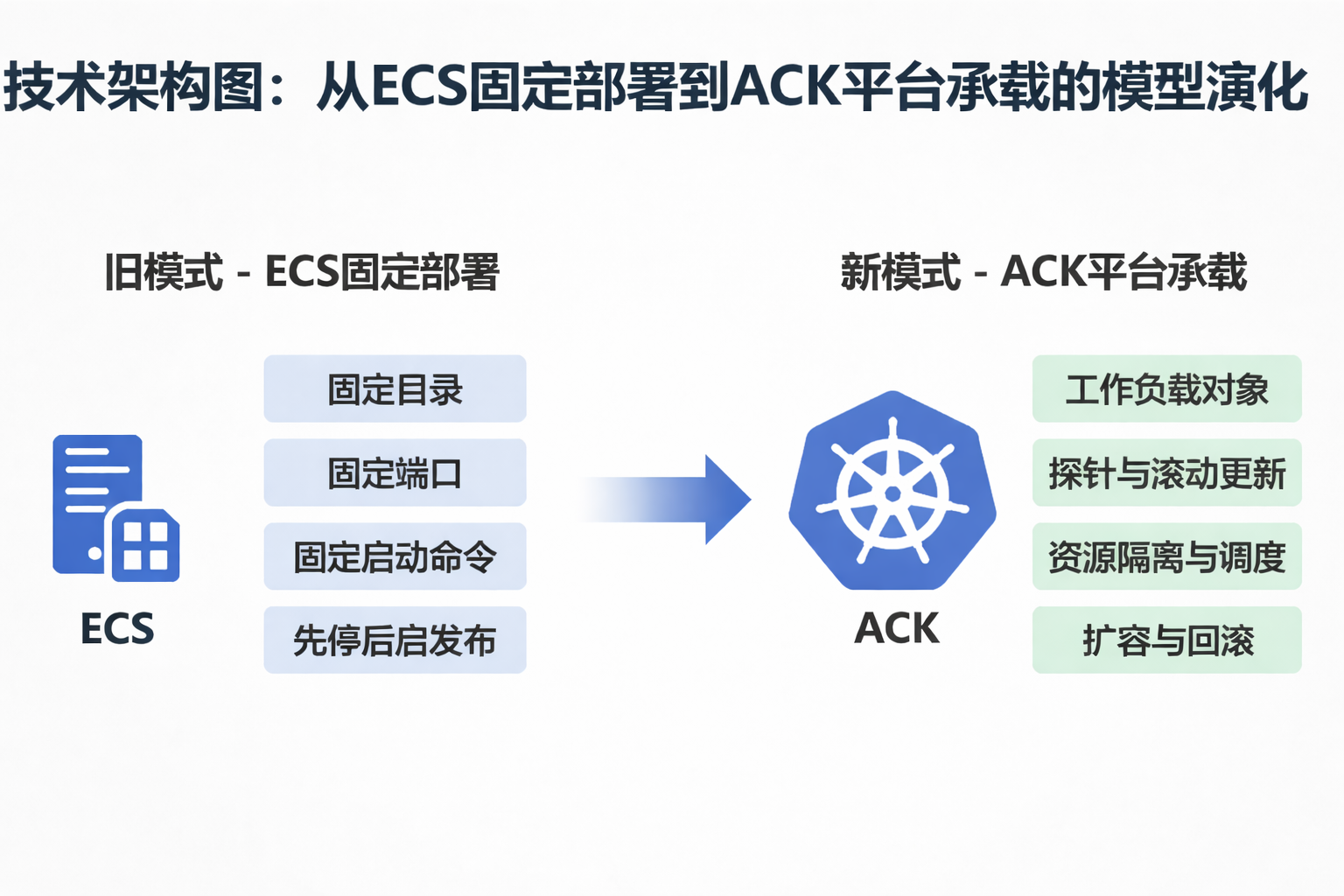
图 1:变化的不是部署目标本身,而是服务第一次从“机器上的固定进程”变成“平台上的工作负载对象”。
1. 改造前:问题不在 ECS,而在固定部署模型
在改造之前,我们的应用主要运行在 ECS 上。部署方式并不复杂:每台 ECS 上按固定目录放置应用包,通过固定端口启动固定的 Java 进程,形式上就是几组明确的 nohup java xxx。构建与发布链路则由 Jenkins 配合 Ansible Playbook 完成。
整体访问链路大致是这样:
SLB -> Nginx(upstream) -> Tomcat(microsvc consumer) -> provider
这套模式在早期阶段并不是不能用,甚至可以说非常符合很多团队最初的工程习惯:结构清晰、部署路径直接、脚本可控、问题也容易通过机器视角来定位。
但随着微服务数量增加、环境逐渐变多、团队协作频率上升,这种模式的问题开始越来越明显。
1.1 固定部署模型让资源无法真正被平台化使用
旧模式的最大特点,是“固定”。
- 固定的 ECS
- 固定的目录
- 固定的端口
- 固定的启动命令
- 固定的部署落点
这意味着服务虽然运行在云上,但它本质上仍然是按照“机器绑定”的方式在组织。某个服务放在哪台机器、占多少资源、和谁部署在一起,往往在很早的时候就已经被写死了。结果就是:热点服务很难快速加副本,冷门服务又可能长期挤占不必要的资源,资源既不灵活,也不高效。
1.2 workload 隔离性差,安全与资源治理能力不足
在 ECS 固定部署模式下,多个 workload 共享同一主机环境,彼此之间的边界相对模糊。哪怕逻辑上它们属于不同服务、不同职责,但从资源视角看,它们仍然更像是“同一台机器上的几组进程”。
这种方式带来的问题并不只是“看起来不够云原生”,而是会直接影响运维治理:
- 资源使用情况难以按 workload 精准观察
- 资源约束和资源抢占控制不方便
- 安全边界天然偏弱
- 一旦机器层面出现波动,影响范围往往比较大
1.3 发布机制本质上仍然是“向前覆盖”
旧的发布模式虽然已经借助 Jenkins 和 Ansible 完成了一定程度的自动化,但从运行时行为来看,它仍然属于典型的“先停后启”。
这意味着每次发布时,服务都会经历一个明确的下线窗口。已有的蓝绿环境在某种程度上能承担一部分“前后脚部署、切流回退”的作用,但它并不能替代单环境本身的工作负载回滚机制。更多时候,旧模式仍然是一种持续向前覆盖发布的方式,而不是一种具备平台级回退能力的方式。
1.4 缺少统一健康检查机制,故障转移能力弱
服务进程启动了,并不等于服务就真的可用;端口监听了,也不代表它已经具备完整的对外服务能力。尤其在微服务场景下,一个实例是否真正 ready,往往不仅取决于 JVM 是否启动完成,还取决于它是否已经完成注册、依赖是否可用、内部初始化是否结束。
而在 ECS 固定部署模式下,这些状态很难被平台统一理解。结果就是:服务健康更多靠经验判断,故障转移也更多依赖人工处理。
1.5 最真实的推动力,其实来自测试联调环境
如果说前面这些问题更多还是架构与运维视角下的长期痛点,那么真正把这件事推起来的,反而是一个非常现实的问题:测试联调环境的协作成本。
测试联调环境没有部署蓝绿双环境,而且很多微服务本身就是单副本。这样一来,团队里任何一个人发布某个微服务,都会因为旧的先停后启机制导致服务中断。测试人员只能等它恢复,联调过程经常被迫暂停。
回头看,这个痛点甚至比“资源利用率低”更能推动改造。因为它不是抽象意义上的平台优化,而是团队每天都会碰到的协作阻塞。
所以回头看,这次改造真正要解决的问题,并不是“换一种部署方式”,而是让服务的发布、探测、扩容、隔离和恢复,第一次拥有平台级能力。
2. 为什么是 ACK:我们需要的不是容器,而是平台
如果目标只是把 Java 进程放进 Docker 里,技术上并不难;但这并不能自动解决旧模式里的那些核心问题。一个被打包成镜像、却仍然以固定思路运行的应用,本质上并没有完成平台化升级。
我们真正需要的,是一套能够承接微服务运行时治理的平台。而 ACK 之所以成为这次改造的核心,不是因为它只是一个托管版 Kubernetes,而是因为它刚好提供了我们最缺的那部分平台能力。
2.1 ACK 解决的不是“能不能跑”,而是“怎么被平台接管”
旧模式里,服务虽然已经自动化部署,但仍然更像是“主机上的进程”;而在 ACK 里,服务开始变成“平台上的工作负载对象”。
一旦服务从进程转变成工作负载对象,它就不再只是一个启动命令,而是开始同时拥有:
- 生命周期
- 副本数
- 更新策略
- 健康状态
- 资源声明
- 调度约束
- 回滚历史
也就是说,平台第一次能够真正理解服务本身,而不是只负责把包发到某台机器上再拉起来。
2.2 ACK 让发布从“先停后启”变成“先启后停”
对我们来说,ACK 最直接、也最有感知的价值之一,就是工作负载的滚动更新能力。
旧模式中,发布往往意味着先停掉旧实例,再启动新实例;而在 Kubernetes 的 Deployment 模型下,发布开始可以在平台控制下变成一种先启后停的过程。Pod 先被拉起,探针通过、状态 ready 后,再逐步承接流量,旧实例随后退出。
这个变化看上去只是发布顺序的变化,但它背后其实是整套运行时承载能力的升级:
- 服务是否 ready 不再靠人工判断
- 发布是否中断不再只能靠蓝绿兜底
- 测试联调环境也第一次拥有了更平滑的上线体验
2.3 ACK 让资源与隔离第一次具备统一表达方式
在 ECS 固定部署模式下,资源和隔离更多是主机视角的问题;而到了 ACK 里,Pod 成了最自然的资源与隔离单元。
这意味着很多原来难以统一表达的约束,开始可以被显式写进工作负载模型里:
- 资源请求与限制
- 多副本调度
- 探针与生命周期
- 挂载与日志路径
- 亲和性与反亲和性
- 不同环境下的运行边界
平台第一次不只是“承载服务”,而是开始“治理服务如何承载”。
2.4 ACK 不是孤立平台,而是后续能力建设的底座
前一篇 Nacos 解决的是:
- 服务怎么跑
- 服务在哪里被发现
而 ACK 解决的是:
- 这些被治理过的服务,最终应该运行在一个什么样的平台上
一旦工作负载标准化、健康检查标准化、资源声明标准化、发布行为标准化,后面的这些能力才真正有了可以持续演进的基础:
- APISIX 入口治理
- 蓝绿与灰度发布
- 日志、指标、链路三层可观测
- GitOps 交付体系
- 更精细的弹性伸缩与容量治理
3. 平台规划:生产、测试、运维支撑三类集群如何分层
当确定要用 ACK 承接微服务运行平台之后,接下来的问题就不再只是“建一个 Kubernetes 集群”,而是:不同环境、不同职责、不同运行面,到底应该怎样被组织在平台里。
在我们的实践里,这一步并不是简单地搭一个集群然后把所有东西都塞进去,而是比较明确地做了分层规划。因为对于微服务体系来说,平台规划本质上也是运行时边界规划。
3.1 生产集群:承接真正的业务运行面
生产集群的职责最重,它不仅承载业务微服务本身,也承载与生产流量直接相关的入口层和部分关键基础组件。
在这个集群里,我们重点组织了几类运行面:
- 入口层:
ingress-apisix - 微服务蓝绿运行面:
green-microsvc、blue-microsvc - 自建中间件:如
nacos、seata - 运维侧组件:如
ops
这样的划分方式,背后其实有几个比较明确的考虑。
首先,入口层需要独立出来。APISIX 作为 Ingress 层,本身承担的是外部流量接入和路由治理能力,它的生命周期、扩缩容和稳定性要求,和业务微服务并不完全一致。把它单独放在 ingress-apisix 命名空间里,更利于独立治理。
其次,蓝绿运行面从一开始就不是一个“逻辑标签”,而是明确的运行空间划分。我们并没有把蓝绿理解成只靠网关规则切一切流量,而是直接把业务运行面拆成了 green-microsvc 和 blue-microsvc 两个 namespace。这样做的好处是,环境边界从入口层就开始向下延伸到工作负载空间本身,发布和流量治理也更容易形成闭环。
再者,中间件和运维组件也不应该与业务 workload 混在一起。像 nacos、seata 这类自建服务,以及 filebeat、otel-collector 这类运维侧组件,本身就有独立的治理需求,把它们分层放置,后面无论是资源控制、故障排查还是版本管理,都会更清晰。
3.2 测试联调集群:面向协作效率而不是生产同构复制
测试联调集群和生产集群的目标并不完全相同。如果说生产环境更强调稳定性、蓝绿切换和运行边界清晰,那么测试联调环境更强调的是环境隔离和协作效率。
因此,我们在测试联调侧并没有简单复制一套“缩小版生产”,而是按照测试场景本身来组织运行空间,比如:
test1-microsvctest2-microsvcjoint-microsvc
这种方式的价值在于,不同测试环境可以在同一套平台上并存,但又具备比较明确的运行边界。而且更重要的是,它直接回应了改造前最真实的那个痛点:测试联调期间的单副本服务发布中断。
3.3 运维支撑集群:让平台能力与业务运行面解耦
除了生产和测试联调,我们还专门规划了运维支撑集群,用来承载可观测等平台侧能力。
如果可观测、日志、链路、告警这些平台能力完全跟业务运行面混在一起,那么随着业务负载增长,平台组件本身的运维也会变得更复杂。把它们独立出来,一方面更方便按平台能力做统一治理,另一方面也让业务运行面和支撑能力之间的边界更清晰。
3.4 Namespace 不是目录划分,而是运行边界表达
如果只从 Kubernetes 使用角度看,namespace 很容易被理解成一个“资源分类目录”;但在我们的实践里,它其实承担了更强的语义职责。
比如在生产环境里:
ingress-apisix表达的是入口运行面green-microsvc/blue-microsvc表达的是蓝绿运行面nacos/seata表达的是基础服务运行面ops表达的是运维侧治理面
也就是说,namespace 在这里不是简单的目录分组,而是在帮助平台表达“谁和谁属于同一运行空间,谁和谁又应该天然隔离”。
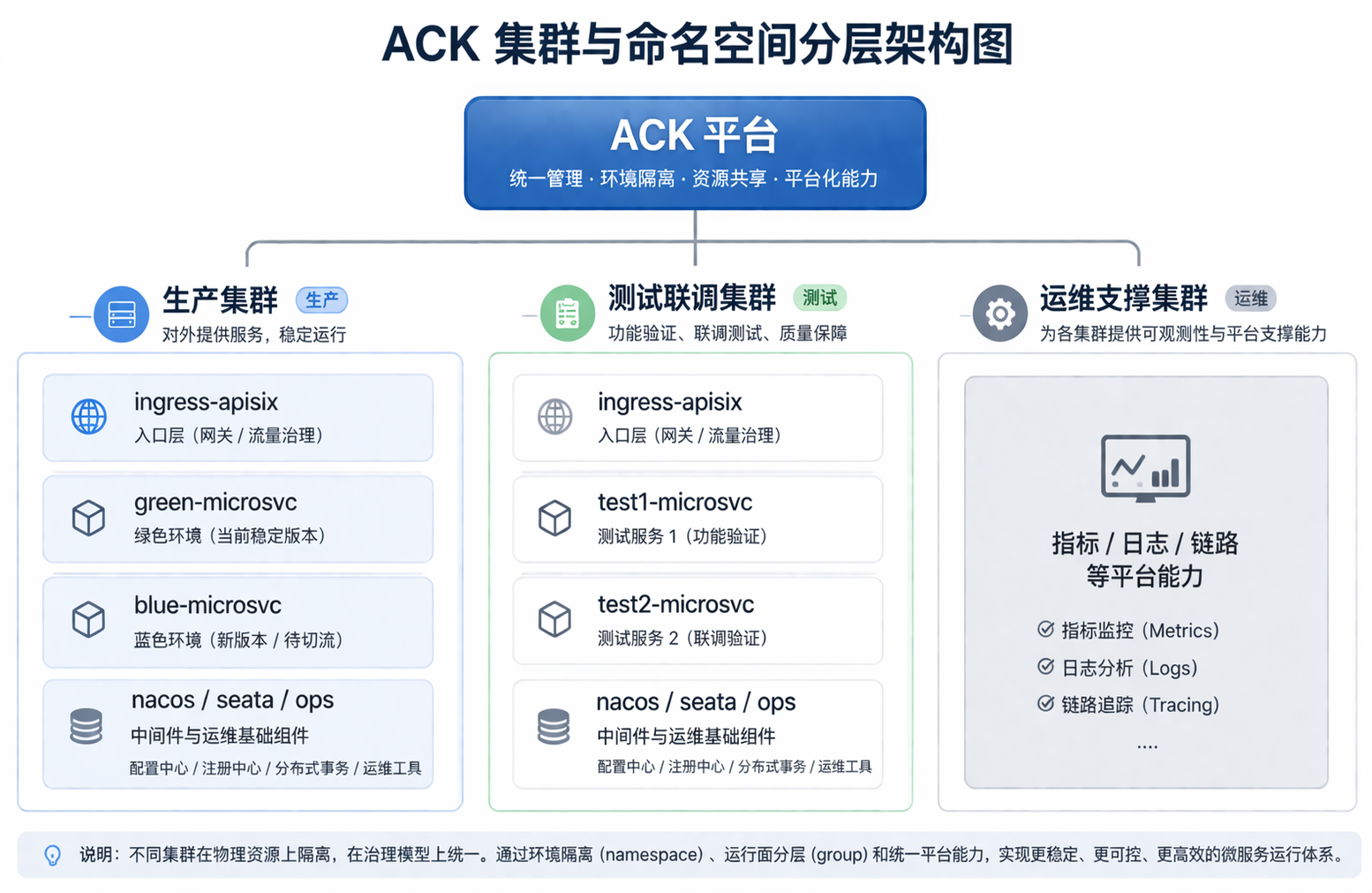
图 2:生产、测试联调、运维支撑三类集群并不是简单的环境复制,而是不同职责的运行面分层。
4. 工作负载设计:把服务差异收敛到平台模型中
当平台结构逐步清晰之后,接下来的关键问题就变成了:微服务到底应该以什么样的工作负载模型运行在 ACK 上。
很多时候,大家一提到 Kubernetes 微服务容器化,第一反应就是 Deployment。从使用频率上看,这个判断并没有错,因为绝大多数无状态微服务确实都适合用 Deployment 承载。但如果把平台化理解成“所有服务都统一抽象成同一种工作负载”,那其实又会丢掉很多真正重要的运行时差异。
在我们的实践里,ACK 平台并不是简单地“一把梭 Deployment”,而是更倾向于按服务运行特征去选择工作负载类型。平台化的关键不是消灭差异,而是把差异收敛到平台可理解、可治理的模型中。
4.1 无状态微服务:以 Deployment 作为默认承载模型
对于绝大多数 Spring Boot / Dubbo 微服务,以及 APISIX 这样的入口层组件,我们都采用了 Deployment 作为默认工作负载模型。
这类服务本身更适合被当作无状态单元来理解,它们最核心的诉求通常不是“实例身份稳定”,而是:
- 副本可以灵活增减
- 可以滚动更新
- 可以在故障时快速被替换
- 可以在调度层做更灵活的资源分配
这正是 Deployment 最适合承接的场景。
4.2 特殊服务为什么要使用 StatefulSet
虽然绝大多数微服务都可以被 Deployment 承载,但也并不是所有场景都应该被强行抽象成无状态。
在我们的业务里,就有一类比较特殊的微服务,它们依赖雪花算法生成分布式唯一 ID,并且在早期运行模式下,需要依托 Zookeeper 注册时绑定一个固定的 worker id。这个 worker id 本身是有运行时身份含义的,因此相关目录和状态不能像普通无状态实例一样随意漂移。
所以在这种场景下,我们采用了 StatefulSet。原因并不是因为它“更高级”,而是因为它更适合表达这种服务真正需要的平台语义:
- 实例身份可预测
- 目录状态可持久化
- 工作负载重建时运行身份更稳定
4.3 工作负载标准化,不等于业务差异消失
平台要尽量给出默认模型,但默认模型不等于唯一模型。服务的差异不应该散落在脚本和人工约定里,而应该被平台收敛到标准对象中去表达。
Deployment 和 StatefulSet 的组合,其实就是这种思路的体现。前者承接绝大多数无状态微服务,后者承接少量具备稳定身份诉求的特殊服务。这样一来,服务差异就不再只是“团队内部知道怎么搞”,而是开始被平台明确理解。
平台化并不意味着消灭差异,而是把服务差异收敛到平台可理解、可治理的工作负载模型中。
5. 发布与流量治理:从先停后启到先启后停
如果说 ACK 平台对我们最直接、也最容易被团队感知到的价值是什么,那么发布模型升级一定排在很前面。
因为在改造前,最真实的痛点之一就是:服务发布会中断环境。无论生产环境还是测试联调环境,只要发布机制仍然是先停后启,那么服务在这段窗口里就一定会不可用。差别只在于,有些环境有蓝绿或多副本可以帮忙兜底,有些环境则只能硬扛。
ACK 真正改变的,就是这件事背后的运行时逻辑。
5.1 从“发布脚本驱动”到“工作负载状态迁移”
旧的发布链路其实已经具备一定自动化能力:
- 触发:Jenkins 手动触发或 GitLab 合并分支
- 构建:Jenkins、GitLab Runner
- 发布:Harbor + Ansible / ArgoCD
从流水线视角看,自动化并不算弱。但问题在于,这种自动化更多还是在解决“如何把新版本发上去”,而不是“服务如何以一种更安全的状态切换进入运行面”。
而当服务开始被 Deployment 这类工作负载承接之后,发布行为就不再只是脚本执行,而开始变成一种由平台管理的状态迁移过程。
5.2 先停后启的问题,本质上不是发布慢,而是服务中断
旧模式里最致命的问题,其实并不是发布速度本身,而是发布行为天然携带中断。服务先停,旧实例先退出;然后再启动新实例,等待新进程起来。
尤其在测试联调环境里,这个问题几乎是“日常可见”的。服务单副本,任何人发版,相关服务都会直接中断;测试人员只能等服务恢复后再继续。这种协作摩擦并不会以“架构问题”的形式表现出来,但它恰恰是推动平台改造最真实的一股力量。
ACK 的价值就在于,它让发布不再天然等于中断。
5.3 Deployment 让发布从先停后启变成先启后停
在 ACK 中,绝大多数无状态微服务通过 Deployment 承接,而 RollingUpdate 策略则让服务发布第一次具备了更平滑的更新方式。
它的核心不是“滚动”这个动作本身,而是:
- 新实例先拉起
- 探针通过后进入 Ready
- 平台再逐步让它承接流量
- 旧实例随后退出
5.4 蓝绿治理不只是入口切流,而是运行面切换
在生产环境中,我们并没有把蓝绿理解成“入口层流量切一切就结束了”。
入口层当然重要,所以我们在 Ingress 层使用了 APISIX,并通过下面几类规则做流量分流:
headerclient ipuri tag
这些规则都非常实用。比如内部测试人员通过 WireGuard VPN 访问时,由于 VPN IP 可控,就很适合做定向流量路由;而第三方平台回调则更适合通过 header 或 uri tag 做区分。
但如果蓝绿只停留在入口层,它其实还是不完整的。因为入口层解决的是:请求先进入哪一套入口;而微服务真正复杂的地方在于:请求进入之后,内部服务之间如何继续维持同样的边界。
这也是为什么在我们的设计里,蓝绿不只是 APISIX 路由规则问题,也是运行面本身的问题。生产环境直接以 green-microsvc 和 blue-microsvc 两个 namespace 承接两套运行空间,这意味着蓝绿不是逻辑标签,而是明确的工作负载运行面。
5.5 为什么蓝环境要访问蓝环境 API,绿环境也一样
在我们的场景里,某些内部微服务之间存在非 Dubbo 的 HTTP API 调用。如果蓝环境的服务在内部又跑去访问了绿环境的 API,那么表面上看入口层蓝绿已经成立,实际上运行时边界却已经混了。
所以我们非常在意一点:
- 蓝环境的微服务应该固定访问蓝环境的 API
- 绿环境的微服务应该固定访问绿环境的 API
这说明蓝绿并不是一个纯入口概念,而是一个需要在入口层、服务运行面和内部调用路径上同时成立的边界模型。
5.6 APISIX 与 Nacos 为什么不直接耦合
在我们的实践里,入口层和服务注册层是刻意分层的。
APISIX 在这里主要基于 Kubernetes Service/Endpoints 做 Tomcat / HTTP 服务发现;而 Dubbo consumer 与 Dubbo provider 之间的注册与发现,则继续走 Nacos。
也就是说,平台里同时存在两层服务发现机制:
- 入口 / HTTP 层:K8s Service Endpoints
- Dubbo RPC 层:Nacos
它们不是竞争关系,而是职责分层关系。
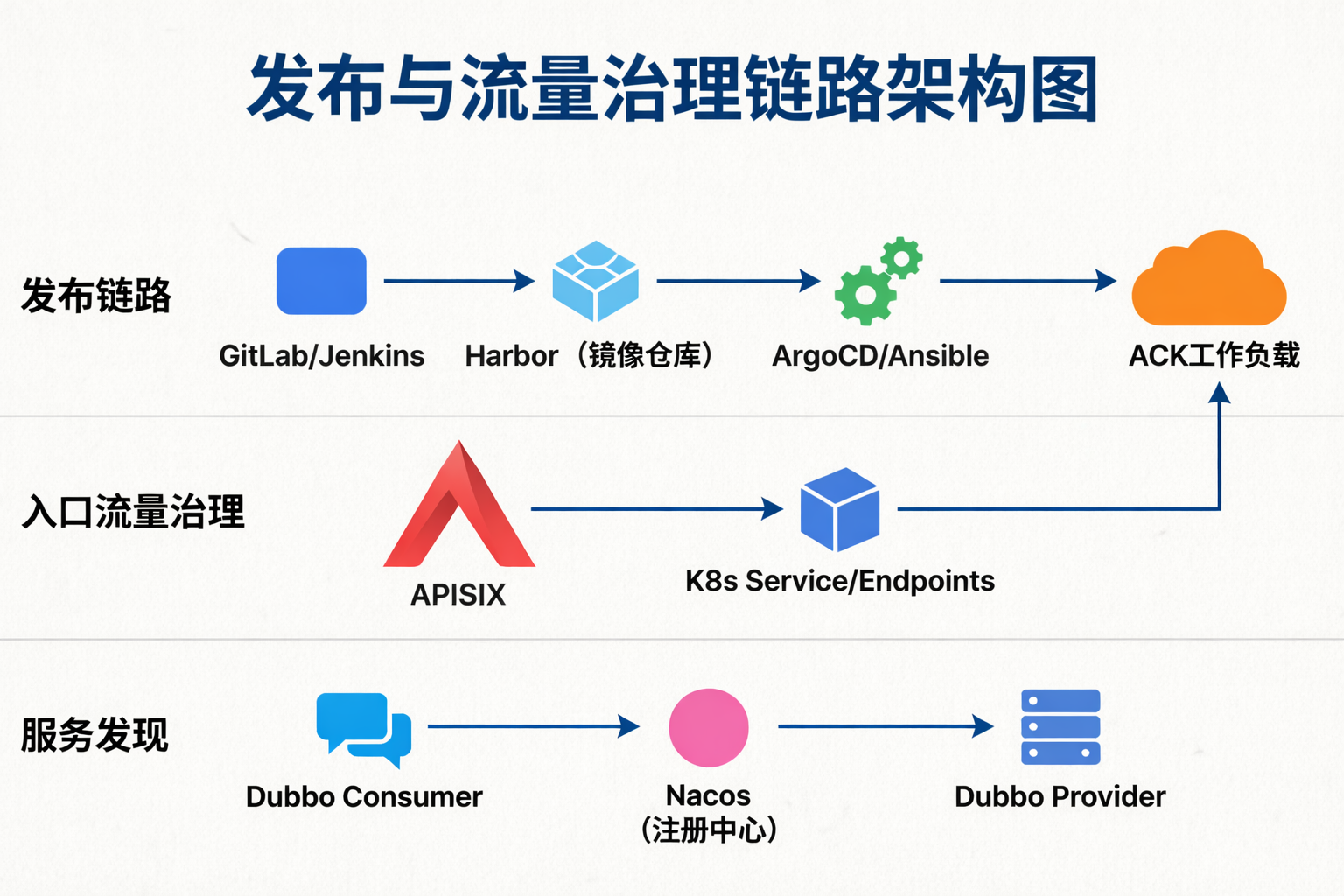
图 3:入口层、工作负载层和服务发现层并不是混在一起的,而是职责清晰、相互衔接。
真正稳定的发布治理,不是把流量切过去,而是让入口路由、运行空间和服务发现边界一起成立。
6. 可观测与运行时治理:探针、日志、指标、链路如何进入平台
很多团队做容器化时,会把可观测理解成“应用上云以后再补的一套外围系统”。但在我们的实践里,ACK 平台带来的一个很重要的变化是:可观测和运行时治理不再只是外围能力,而是开始进入工作负载默认设计的一部分。
6.1 探针不是简单探活,而是平台对服务状态的理解
在 Kubernetes 里,livenessProbe、readinessProbe 和 startupProbe 是最基础的能力,但真正怎么用,差别其实很大。
对我们来说,探针最重要的价值,不是“平台能不能重启一个坏掉的容器”,而是平台第一次开始真正理解:一个服务什么时候算启动完成、什么时候算可用、什么时候才可以接流量。
其中最值得展开的其实是 readinessProbe。
很多时候,服务只要端口通了,就会被当成 ready;但在 Dubbo 微服务场景里,端口通了并不等于服务真的可用。因为它还可能没有完成注册,或者虽然 JVM 已经启动,但对下游消费者来说,它仍然不可发现。
所以我们的 readinessProbe 并不是简单地探一个端口,而是依赖一个额外的 sidecar 去检查服务是否真正完成了注册。
6.2 readiness 的关键,不是进程活着,而是服务是否真正进入运行面
在我们的部署里,Pod 中除了业务容器之外,还会有一个 nacos-registry-check sidecar。它的职责并不复杂,但很关键:在业务容器启动后,辅助判断该实例是否已经真正完成服务注册,并把结果以文件形式写入共享目录。随后,业务容器的 readinessProbe 再通过检查 /etc/nacos/isRegistered 这个标记文件,来决定是否进入 Ready。
这背后的设计思想其实很明确:
- 业务进程启动,不等于服务已可用
- 端口监听,不等于服务已完成注册
- 只有真正进入服务发现体系后,实例才应该接流量
6.3 日志体系:从主机文件到平台统一采集
在我们的运行模型里,业务日志会落到宿主机目录,然后通过 Filebeat DaemonSet 做节点级采集,再跨集群进入 Kafka,随后由 Logstash 写入 Elasticsearch,最终在 Kibana 中检索和分析。
链路大致如下:
Filebeat(DaemonSet) -> Kafka -> Logstash -> Elasticsearch -> Kibana
这里的关键点并不只是“用了 ELK”,而是日志收集开始围绕平台工作负载组织起来。比如我们会通过 hostPath + subPathExpr 的方式,把日志目录按 namespace_podname 的维度进行组织,让日志归属和运行实例天然关联。
6.4 指标体系:平台内部采集,跨集群统一汇聚
在 ACK 内部,Prometheus 负责采集 Kubernetes 与工作负载相关指标;然后通过 remote_write 将数据写入跨集群部署的 VictoriaMetrics,再由 Grafana 统一展示。
Prometheus(k8s 内部) -> remote_write -> VictoriaMetrics -> Grafana
这种方式很适合已有的运维支撑集群思路:采集能力贴近运行面,长期存储和统一展示则与业务集群解耦。
6.5 链路体系:为什么 OTel Java Agent 不应该进业务镜像
在链路侧,我们采用的是 OTel Java Agent 注入模式,整体链路大致是:
OpenTelemetry Java Agent -> OTel Collector(k8s 内) -> Kafka -> OTel Collector -> ClickHouse / Tempo -> Grafana
但真正值得写的,并不是“用了 OpenTelemetry”,而是我们选择了怎样的注入方式。
在我们的 Pod 设计里,OTel Java Agent 并没有直接封装到业务镜像中,而是通过 init 容器把 agent 包拷贝到共享卷中,再通过环境变量和 JAVA_OPTS 的方式注入到业务进程里。
这个设计背后的治理思路非常清楚:
- 运维侧能力与业务镜像解耦
- 不同环境可以灵活决定是否启用链路
- OTel 升级不必绑定业务镜像重构
- 平台更容易统一管理可观测注入策略
6.6 可观测接入的本质,是运行时治理前置
把探针、日志、指标、链路这些点放在一起看,就会发现 ACK 对可观测最大的价值,并不只是“部署方便”,而是它让可观测开始进入工作负载默认设计。
这意味着很多原来只能事后补救的问题,开始可以在运行时层面被提前约束:
- 服务什么时候接流量
- 服务日志如何被稳定采集
- 指标如何与工作负载关联
- 链路能力如何在不污染业务镜像的前提下注入
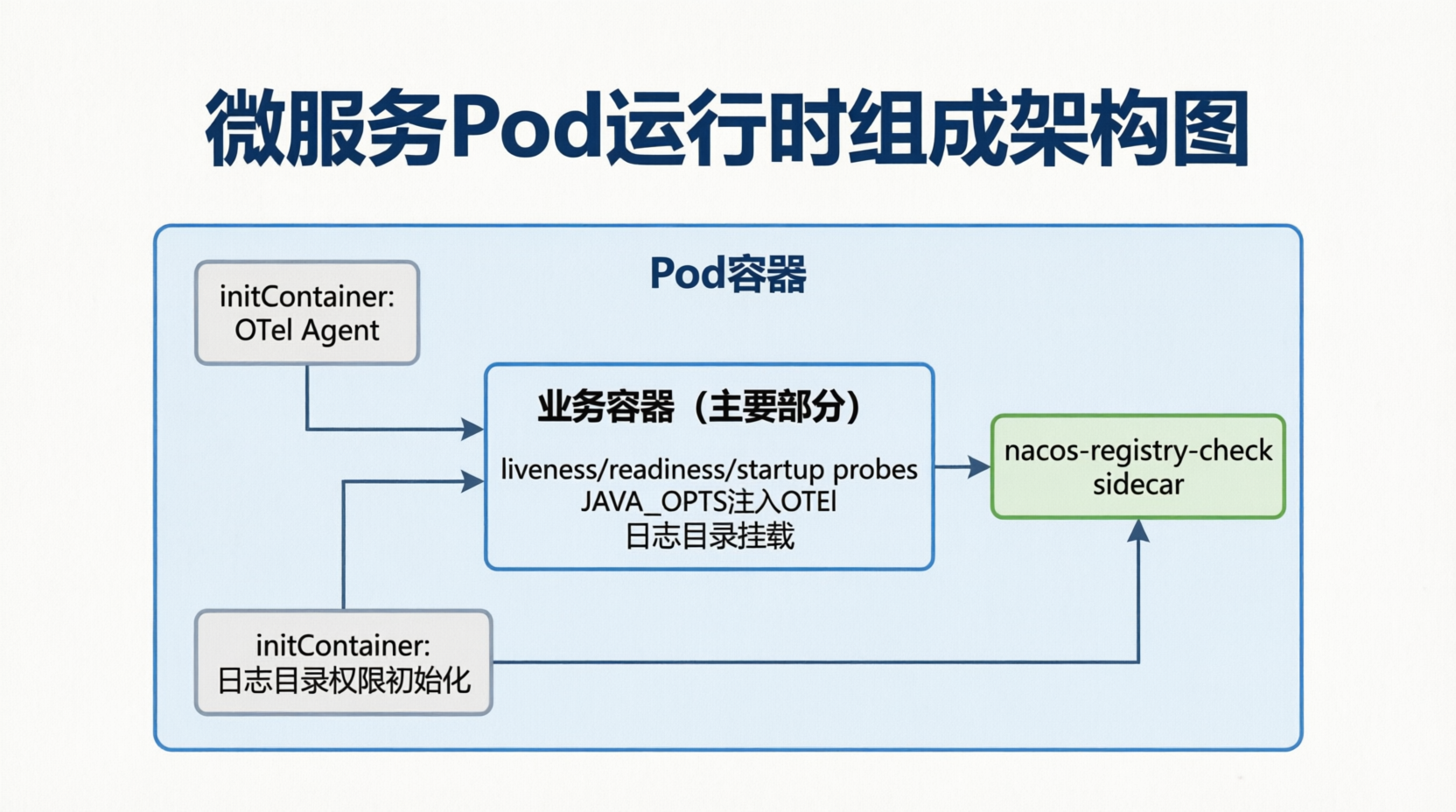
图 4:Pod 在这里已经不是单纯的“装应用的壳”,而是承载探针、注册检查、日志、链路注入等治理能力的运行时单元。
平台的价值,不只是把 Pod 拉起来,而是让服务以什么状态接流量、如何被观测、如何被判断,都进入统一的运行时治理模型中。
7. 扩缩容与高可用:从固定资源到弹性承载
如果说工作负载模型、发布治理和可观测接入解决的是“服务如何在平台上被稳定承接”,那么扩缩容与高可用解决的就是另一件同样重要的事:系统能不能根据负载变化和故障场景,动态调整自身的承载能力。
在旧的 ECS 固定部署模式下,资源更多是“机器维度”的。扩容意味着新增机器、部署服务、调整落点;缩容则意味着回收机器或人工整理部署关系。这样的方式当然也能扩,但它的粒度较粗、响应较慢,而且很难让服务副本数、资源容量和节点规模形成一套协同变化机制。
而在 ACK 里,这件事第一次被拆成了多个层次来治理。
7.1 扩容不再只是“加机器”,而是工作负载与基础设施协同变化
在平台化之后,扩容开始至少存在两层含义:
- 工作负载层:Pod 副本数如何变化
- 基础设施层:节点规模如何变化
这意味着我们不再只是从“机器够不够”去理解容量,而是开始从“工作负载如何承接流量变化”去理解扩容。
7.2 扩缩容不是一个按钮,而是多层能力协同
在我们的平台实践里,扩缩容并不是只靠某一个单点能力完成,而是由多种机制共同协作。
第一类,是基于业务经验的 Cron 缩扩容。
第二类,是基于指标的 KEDA 缩扩容。
第三类,则是基础设施层的伸缩,会结合 Terraform 从云资源层面对 ECS 做上下线调整。
把这三类能力放在一起看,就会发现我们真正构建的并不是“某个扩容工具”,而是一套多层协同的容量治理方式:
Cron负责承接预期内变化KEDA负责承接指标驱动变化- Terraform + ECS 负责承接基础设施层资源供给变化
7.3 高可用不只是多副本,而是避免同类服务“一锅端”
很多时候,一提到高可用,大家首先想到的是多副本。多副本当然是基础,但对平台来说,仅有多副本还不够。因为如果多个副本最终仍然被调度到同一类故障域里,那么它们在关键时刻很可能会一起失效。
所以在 ACK 平台上,高可用真正值得关注的,并不只是“有几个 Pod”,而是这些 Pod 如何被调度、如何分散、如何在节点异常时继续维持服务能力。
7.4 资源利用率提升,本质上是平台调度能力变强了
这次 ACK 改造带来的一个非常直观的结果,是单节点资源利用率明显提升。在保留预留资源、不刻意过度挤占的前提下,单节点资源利用率从大约 40% 提升到了 70%。
这个数字并不是因为“换了容器以后 magically 更省资源”,而是因为平台终于开始具备以下能力:
- 资源请求与实际 workload 更匹配
- 服务副本可以更灵活分布
- 热点与冷门服务不再必须按机器绑定
- 资源可以围绕运行时负载动态调度
容器平台真正改变的,不是部署命令,而是系统第一次具备了按负载和故障场景动态调度资源的能力。
8. 一个典型部署设计:为什么这个 Pod 要这样设计
如果前面几节更多是在讲平台层面的能力,那么这一节想落回一个更具体的视角:一个微服务 Pod 在我们的平台里,究竟是如何被设计出来的。
8.1 标签不是装饰,而是运行时语义的一部分
在工作负载对象里,我们会比较明确地使用这类标签:
apprun_envsvc_type
这些标签当然首先服务于 Kubernetes 选择器和资源归属,但它们的价值并不止于此。对平台来说,这些标签也在表达运行时语义:这个实例属于哪个服务、它处于哪个运行环境、它扮演的是 provider 还是 consumer 角色。
8.2 探针设计的关键,不是端口通不通,而是服务是否真正 ready
livenessProbe 更多是在判断这个实例还“活着没有”,比如 Dubbo 服务端口是否还可探测;而 readinessProbe 则完全是另一层含义:它要回答的是,这个实例现在是否真的已经准备好接流量。
在我们的设计里,readinessProbe 并不直接探业务端口,而是通过检查 /etc/nacos/isRegistered 来判断服务是否已经完成注册。这个标记文件由 nacos-registry-check sidecar 辅助生成,目的是让平台看到的 Ready,不再只是“JVM 启动了”,而是“服务已经真正进入服务发现体系”。
8.3 sidecar 和 initContainer 承担的是运行时治理,而不是功能堆叠
这个 Pod 里除了业务容器外,还有几类辅助容器:
- 日志目录权限初始化的 initContainer
- OTel Java Agent 注入的 initContainer
nacos-registry-checksidecar
如果只从“让应用跑起来”的角度看,这些容器似乎都不是必须的;但如果从平台治理角度看,它们恰恰是把很多原来散落在脚本、镜像或人工操作里的逻辑,前置到了运行时单元里。
8.4 卷设计体现的是运行时边界,而不是文件挂载技巧
Pod 里的卷设计同样很有代表性:
hostPath用来承接日志目录emptyDir用来承接 OTel agent 和 nacos 状态共享ConfigMap用来注入 nacos 地址配置
如果只是从配置项层面看,这似乎只是几种常见卷类型的组合;但从治理角度看,它们分别承接了不同的运行时边界。
8.5 entrypoint 脚本其实是在连接平台上下文与应用上下文
在我们的 entrypoint 中,除了启动 Java 进程本身,还会把一些平台上下文通过 JVM 参数传给应用,例如:
dubbo.registry.groupspring.cloud.nacos.discovery.groupPOD_NAMEOTEL_SERVICE_NAME
这里的关键不在于“脚本里多加几个参数”,而在于应用开始显式接收平台上下文。环境、分组、可观测标识等信息,不再只是运行平台自己知道,而是会继续进入应用运行时,参与服务发现、环境治理和链路标识。
一个好的 Pod 设计,不只是把进程跑起来,而是把发布、探测、可观测、注册发现和环境治理都前置到运行时单元里。
9. 实际收益:这次 ACK 改造到底带来了什么
回头看这次 ACK 改造,真正值得复盘的,不是用了什么技术名词,而是系统在运维实践和架构演进层面,到底发生了哪些实质变化。
9.1 发布收益:服务上线开始从中断动作变成平台行为
最直接的收益,是发布行为本身发生了变化。滚动更新、探针控制、Ready 后接流量、原生回滚,这些能力叠加起来的结果是:服务上线不再天然意味着中断。
9.2 资源收益:资源利用率显著提升,但不是靠“硬挤”
在保留必要预留资源、不刻意过度压榨节点的前提下,单节点资源利用率从大约 40% 提升到了 70%。这不是因为“换了容器以后 magically 更省资源”,而是因为平台终于能更合理地组织 workload 与资源关系。
9.3 弹性收益:系统开始具备快速响应访问变化的能力
基于历史经验的定时缩扩容、基于指标的 KEDA 伸缩、以及底层 ECS 资源上下线能力结合起来,让系统第一次开始具备一种真正的平台级弹性能力。
9.4 稳定性收益:故障转移和运行边界开始由平台承接
探针和工作负载模型让平台能更准确地判断实例状态;Pod / Node 亲和性与分散调度,又让服务在节点异常时不至于整体受损。再加上镜像机制带来的环境一致性、GitOps 与原生回滚并存带来的可回退能力,服务整体的可恢复性和可控性都明显增强。
9.5 典型案例:扩缩容和故障承接终于形成闭环
基础设施层可以通过 Terraform 对 ECS 做上下线调整;工作负载层可以由 K8s 对热点微服务 Pod 副本数做出变化;而在故障场景中,Pod / Node 的调度和分散机制,又能避免某类服务实例被一锅端。
从结果上看,这意味着系统已经不再只是“能运行”,而是开始具备:
- 面对流量变化的自适应能力
- 面对故障场景的承接能力
- 面对发布变化的回退能力
ACK 带来的最大变化,不是“部署更现代了”,而是发布、资源、弹性和稳定性终于开始建立在同一套平台能力之上。
10. 结语:ACK 不是终点,而是平台化治理的承载底座
回头看这次从 ECS 固定部署模式走向 ACK 微服务平台的过程,我们越来越清楚地意识到:真正被替换掉的,并不是某一种部署形式,而是一种已经不再适合微服务继续演进的运行时承载方式。
在旧模式里,服务更多是固定机器上的固定进程;而在 ACK 里,服务第一次变成了平台上的工作负载对象。它有生命周期、有健康状态、有副本语义、有更新策略,也开始具备弹性伸缩、原生回滚、调度分散和统一可观测接入能力。
也正因为这样,这次改造的意义并不只是“应用跑进了 Pod”,而是:
- 发布从脚本动作变成平台控制下的状态迁移
- 运行面从固定机器变成工作负载对象集合
- 可观测从外围系统变成运行时默认能力
- 弹性和高可用从人工操作变成平台承接能力
如果说第一篇 Nacos 那篇解决的是:
- 服务怎么跑
- 服务在哪里被发现
那么 ACK 这一篇真正解决的就是:
- 这些被治理过的微服务,最终应该运行在一个什么样的平台之上
从这个角度看,ACK 在这里并不是终点。它更像是后续很多平台能力得以成立的承载底座:
- APISIX 入口治理
- 蓝绿与灰度发布
- 三层可观测平台
- GitOps 交付体系
- 更进一步的 AIOps / AI RCA
所以如果要用一句话来总结这次改造,我更愿意这样说:
ACK 的价值,不是让微服务“跑在容器里”,而是让微服务第一次真正“运行在平台上”。
小结
这次 ACK 改造最值得复盘的,不是 Kubernetes 本身,而是微服务运行时承载模型的变化:
- 服务从机器上的固定进程,变成平台上的工作负载对象
- 发布从先停后启,变成平台控制下的滚动状态迁移
- 入口流量、服务发现、运行空间开始形成边界闭环
- 可观测、扩缩容、回滚和高可用开始成为平台默认能力
延伸阅读
- 下一篇会继续写 APISIX 与微服务入口治理
- 蓝绿灰度发布为什么不只是网关规则问题
- 指标、日志、链路三层可观测如何与 ACK 工作负载联动
- 从 Jenkins 到 GitOps 的交付治理如何接入容器平台
评论区