


Oozie 的安装
oozie是一个基于Hadoop的工作流引擎,也叫任务调度器,它以xml的形式写调度流程,可以调度mr、pig、hive、shell、jar和spark等。在工作中如果多个任务之间有依赖执行顺序要求,可以使用oozie来进行调度执行。
-
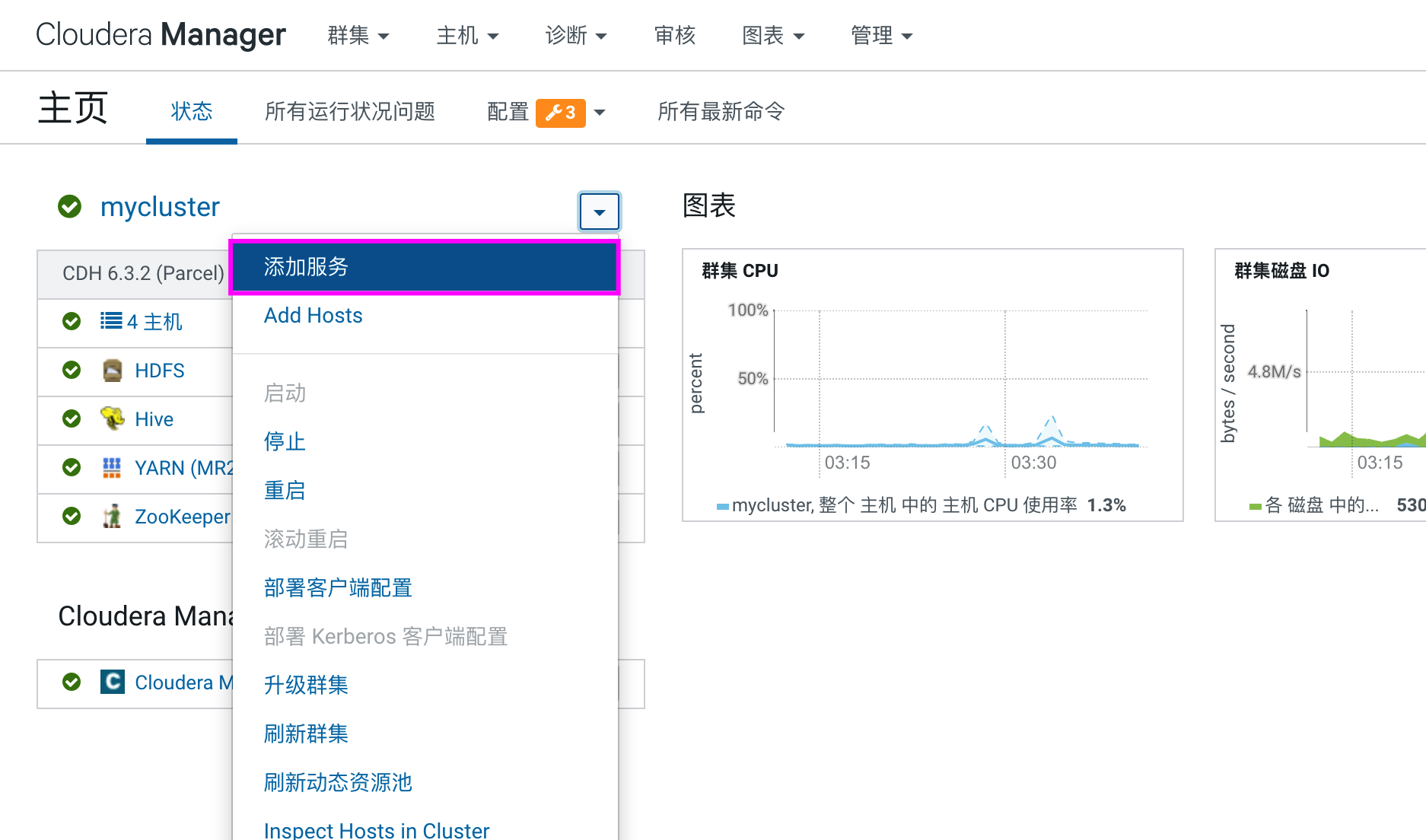
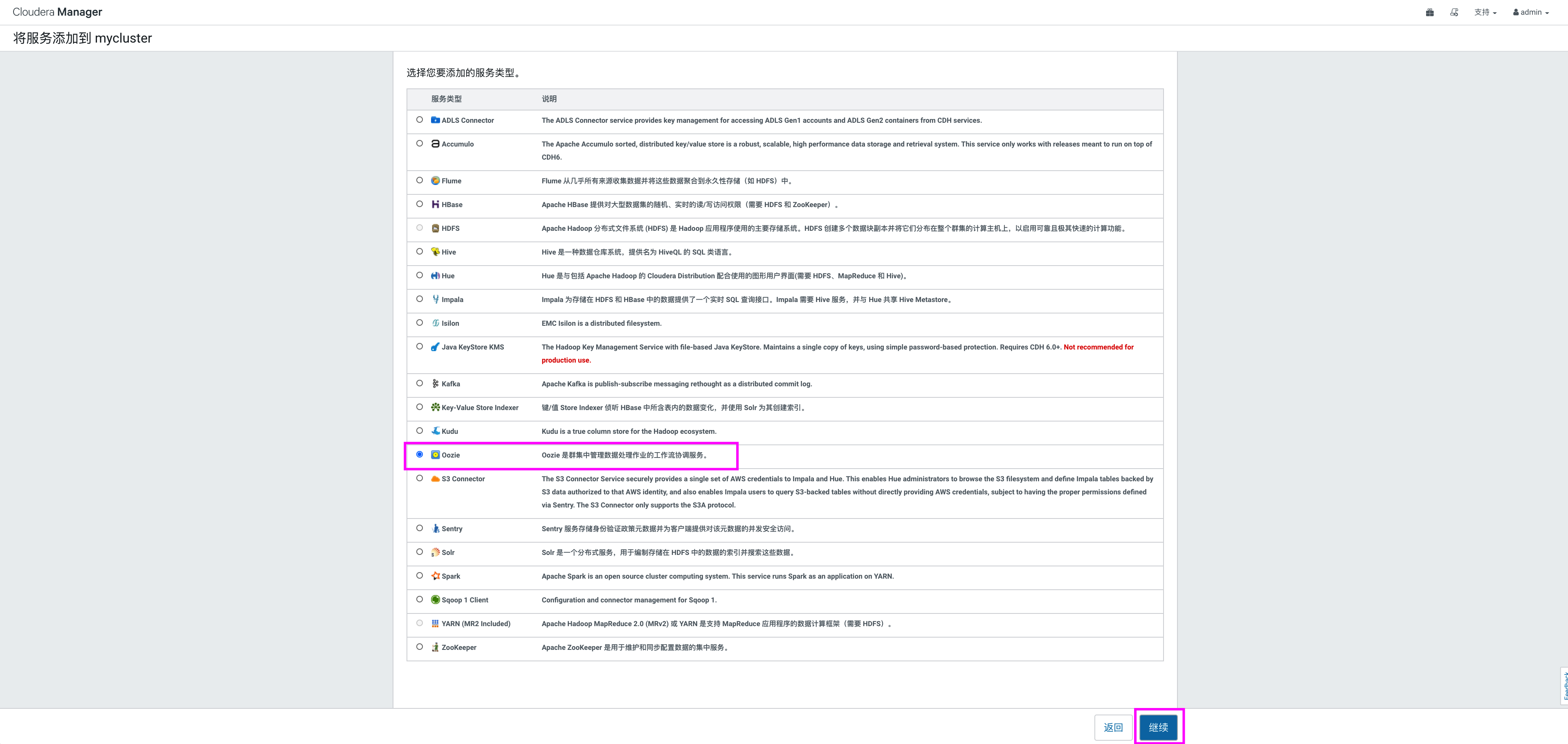
选择集群,添加 oozie 服务
-
添加服务向导
选择依赖
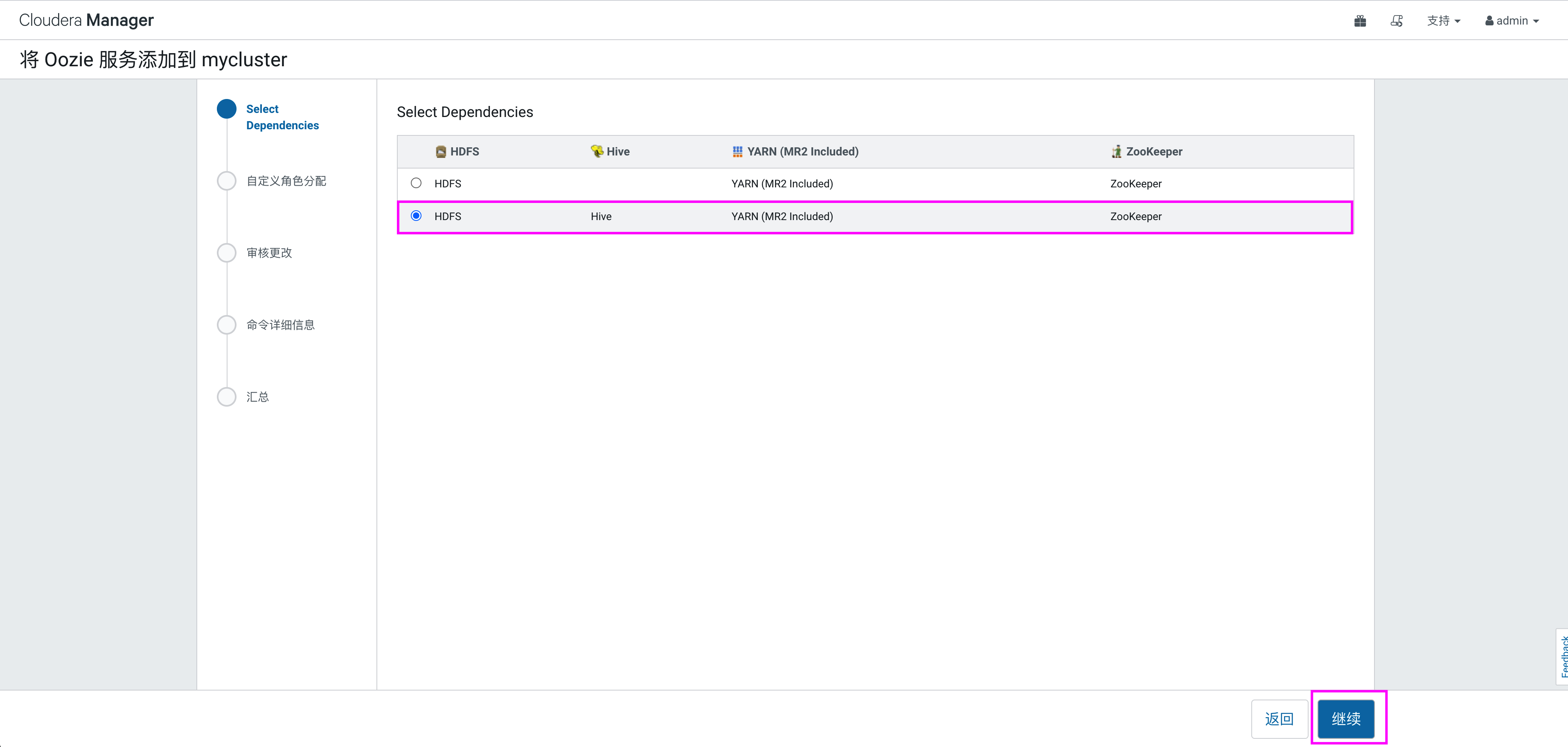
选择节点,分配oozie角色:
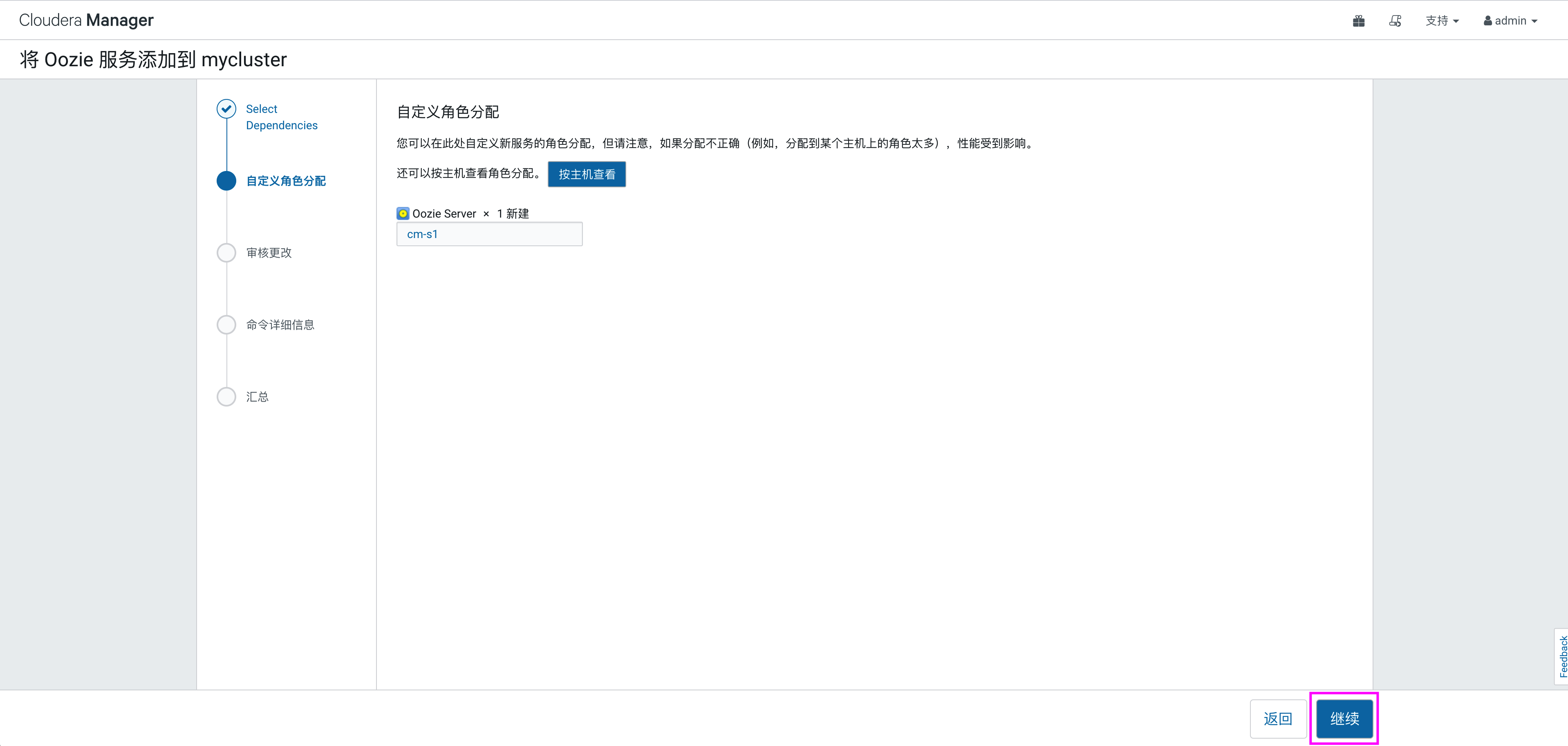
当点击“继续”后,需要给oozie配置数据库,需要在cm-s1节点上连接mysql,执行创建数据库及分配权限语句:
[root@cm-s1 ~]# mysql -hcm-s1 -pAz123456_ -e "create database oozie DEFAULT CHARACTER SET utf8;grant all on oozie.* TO 'oozie'@'%' IDENTIFIED BY 'Az123456_';flush privileges;"
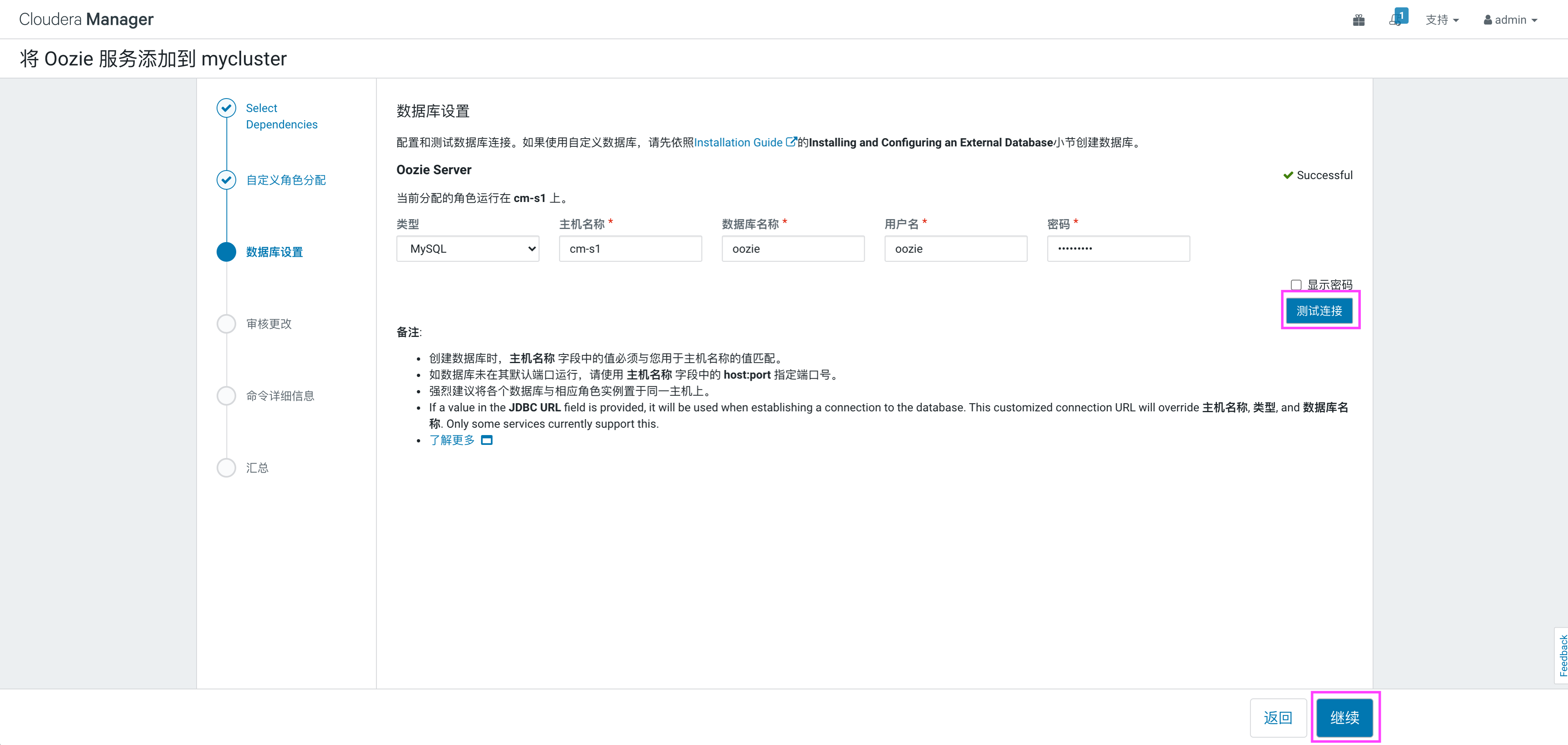
在弹出的页面中选择数据库,填写用户名及密码,点击“测试连接”,测试数据库连接成功后,点击“继续”:
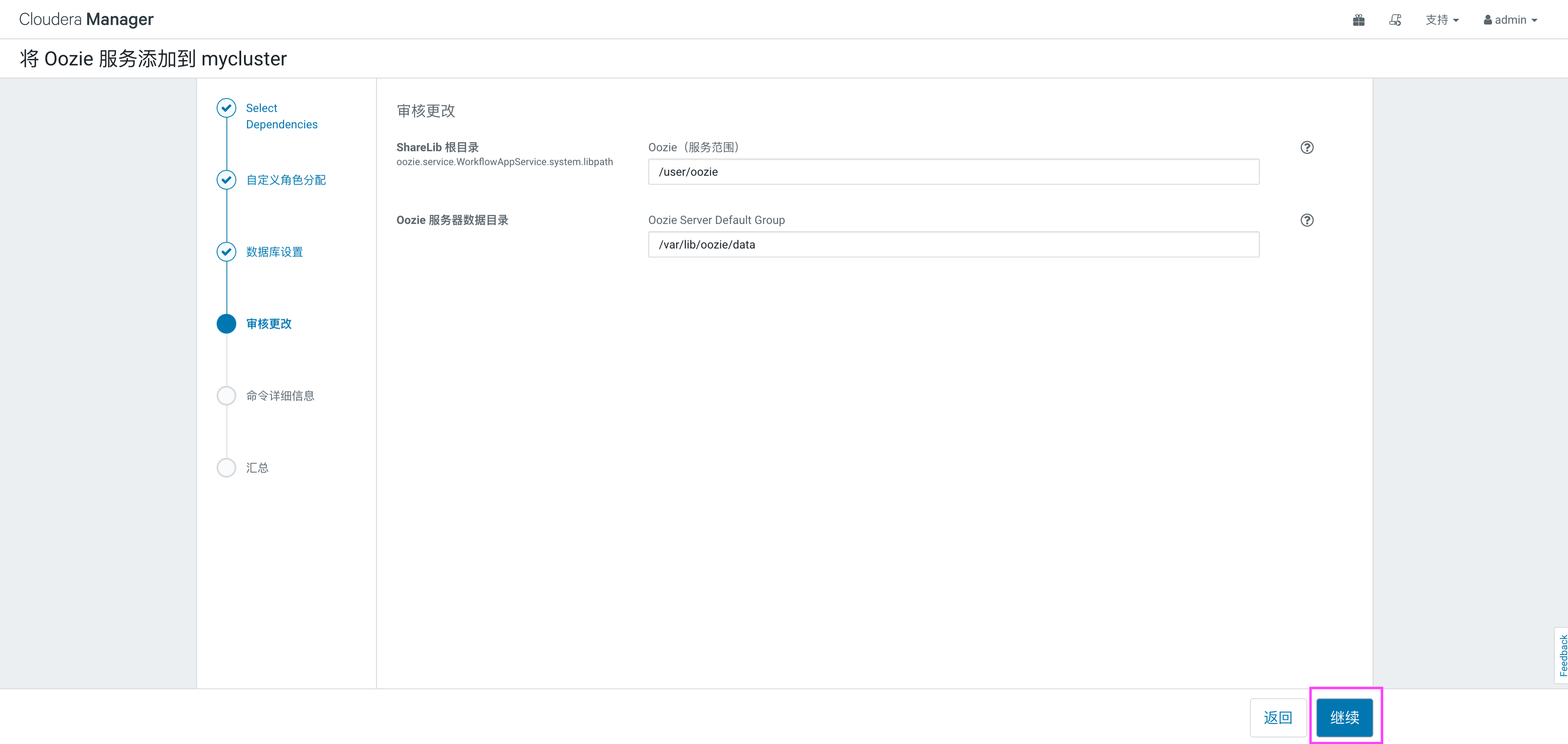
在弹出的页面中,选择默认oozie使用的数据目录,默认即可,点击“继续”:
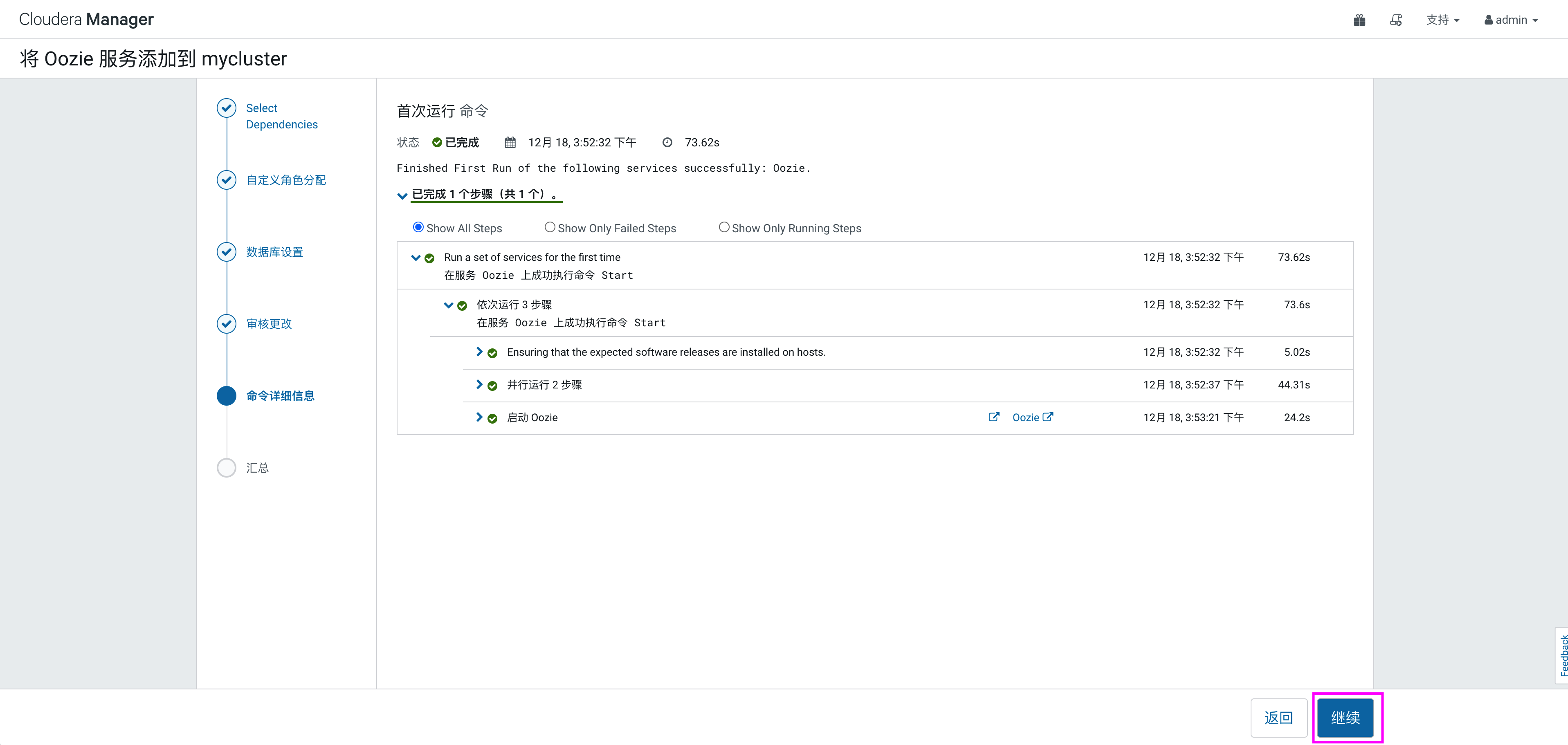
等待服务向导完成,点击“继续”->“完成”,完成oozie安装。
Oozie 的使用
Oozie是用于 Hadoop 平台的开源的工作流调度引擎。 用来管理Hadoop作业。 属于web应用程序,由Oozie client和Oozie Server两个组件构成。 Oozie Server是运行于Java Servlet容器(Tomcat)中的web程序。
-
Oozie 作用:
- 统一调度hadoop系统中常见的mr任务启动、hdfs操作、shell调度、hive操作等
- 使得复杂的依赖关系、时间触发、事件触发使用xml语言进行表达
- 一组任务使用一个DAG来表示,使用图形表达流程逻辑更加清晰
- 支持很多种任务调度,能完成大部分hadoop任务处理
- 程序定义支持EL常量和函数,表达更加丰富
-
Oozie 中的概念:
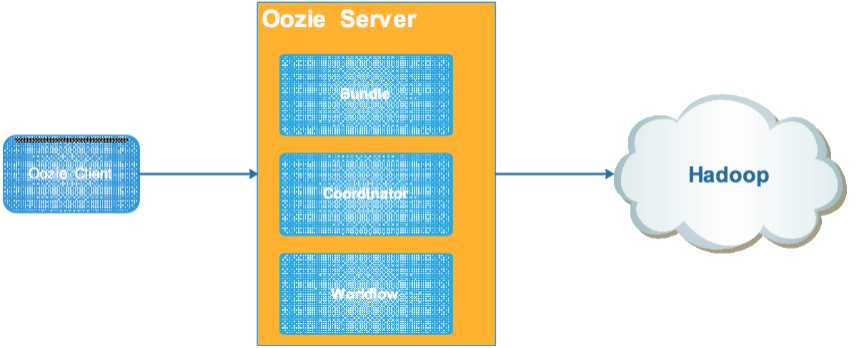
- workflow: 工作流,顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个)。
- coordinator: 多个 workflow 可以组成一个 coordinator,可以把前几个 workflow 的输出作为后一个 workflow 的输入,也可以定义 workflow 的触发条件,来做定时触发。
- bundle: 是对一堆 coordinator 的抽象,可绑定多个 coordinator。
-
Oozie Web 控制台
- 将 ext-2.2 解压到对应目录
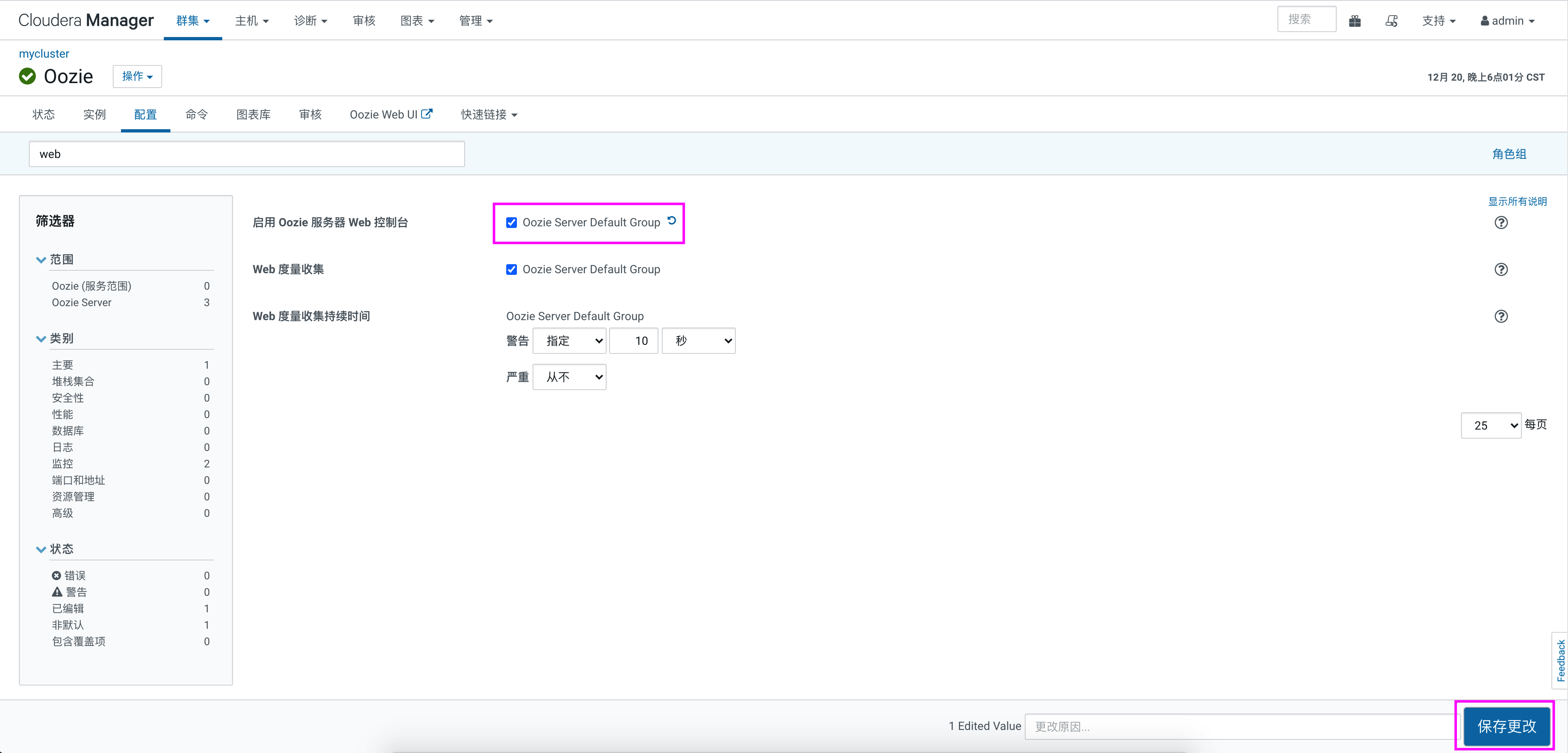
如果使用web控制台,还需要在oozie安装节点cm-s1上将“ext-2.2”解压到路径“/var/lib/oozie”目录下,首先将“ext-2.2”上传到cm1节点上,在cm1节点上执行如下命令:[root@cm-s1 ~]# wget https://archive.cloudera.com/gplextras/misc/ext-2.2.zip [root@cm-s1 ~]# unzip ext-2.2.zip -d /var/lib/oozie/ [root@cm-s1 ~]# chown -R oozie:oozie /var/lib/oozie/ext-2.2 - 启用 Oozie 服务器 Web 控制台
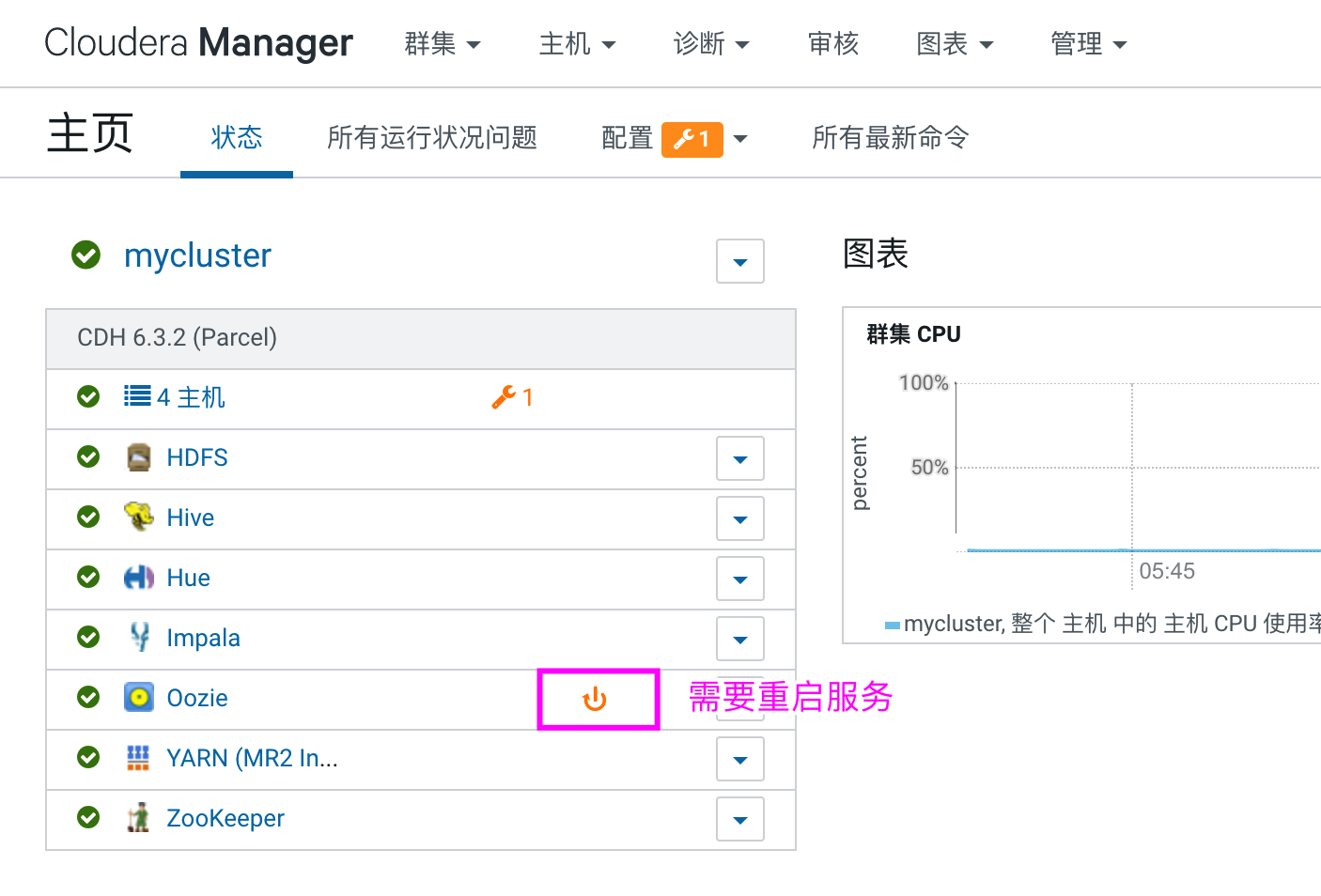
在 CDH 中进入 oozie,点击配置,找打“启用 Oozie 服务器 Web 控制台”选项,开启,保存更改之后,重启 oozie 服务即可。
- 将 ext-2.2 解压到对应目录
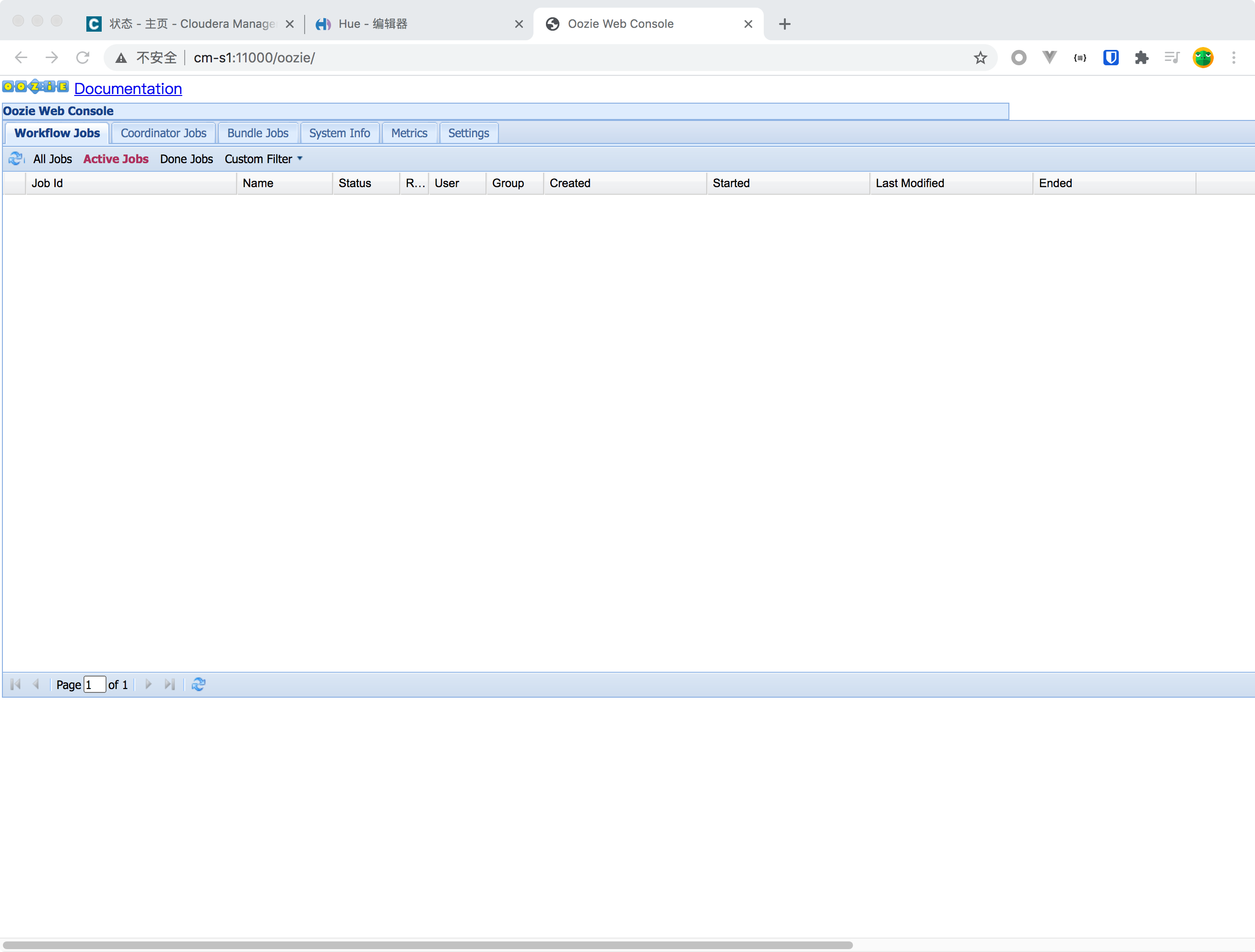
- 浏览器或者CDH页面访问 oozie 的webui,地址http://cm-s1:11000
-
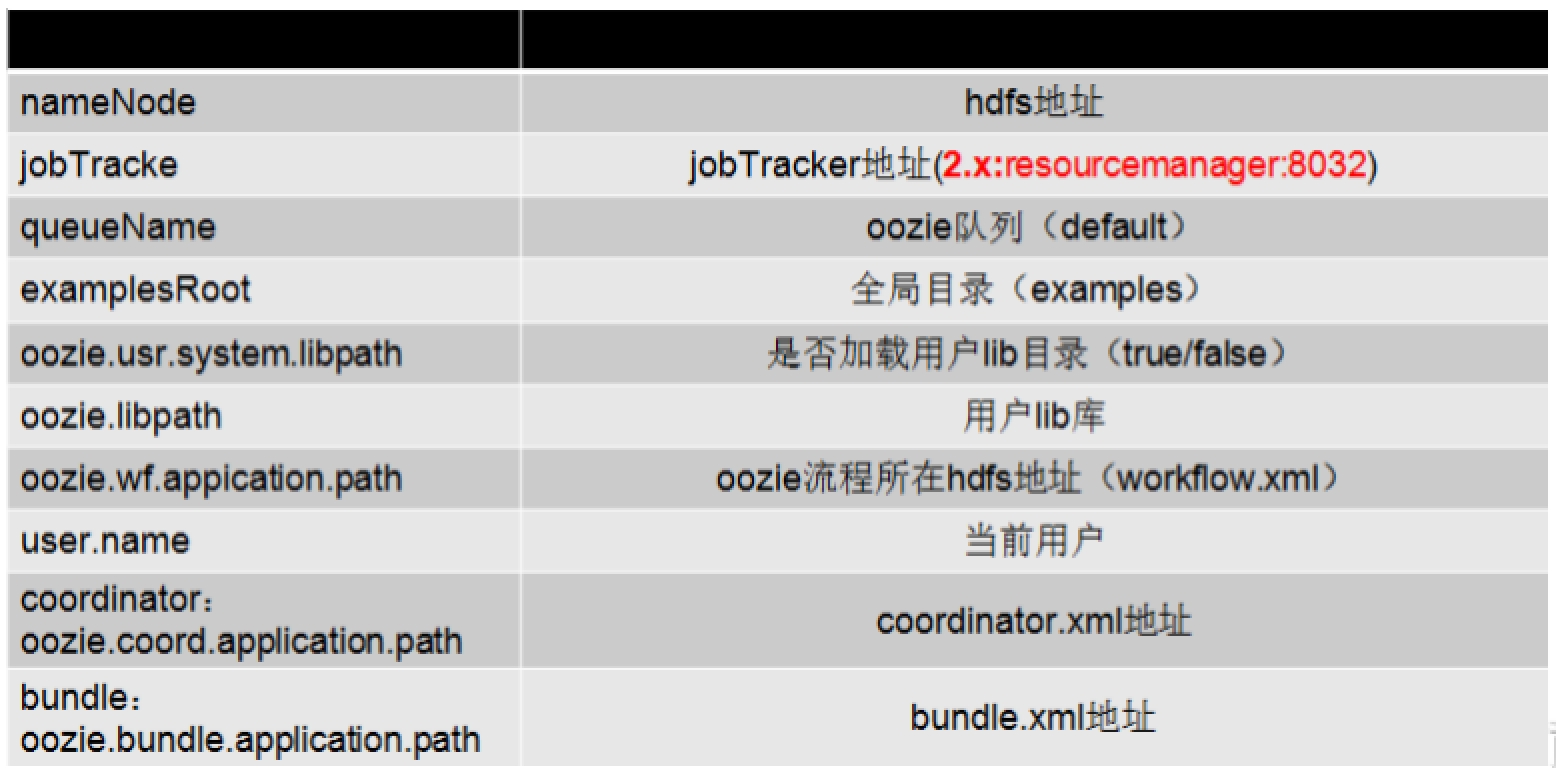
Oozie job.properties 文件参数
-
Oozie 提交任务命令
默认在 CDH 中安装了 oozie 后,每台节点都可以当做客户端来提交oozie任务流任务。启动任务,停止任务,提交任务,开始任务和查看任务执行情况的命令如下:
启动任务中的--run 包含了submit和start操作。
启动任务:
oozie job -oozie http://ip:11000/oozie/ -config job.properties -run
停止任务:
oozie job -oozie http://ip:11000/oozie/ -kill 0000002-150713234209387-oozie-oozi-W
提交任务:
oozie job -oozie http://ip:11000/oozie/ -config job.properties -submit
开始任务:
oozie job -oozie http://ip:11000/oozie/ -config job.properties -start 0000003-150713234209387-oozie-oozi-W
查看任务执行情况:
oozie job -oozie http://ip:11000/oozie/ -config job.properties -info 0000003-150713234209387-oozie-oozi-W
-
Oozie 提交任务流
Oozie 提交任务需要两个文件,一个是 workflow.xml 文件,这个文件要上传到 HDFS 中,当执行 oozie 任务流调度时,oozie 服务端会在从 xml 中获取当前要执行的任务。
另一个 job.properties 文件,这个文件是 oozie 在客户端提交流调度任务时告诉 oozie 服务端 workflow.xml 文件在什么位置的描述配置文件。
配置 workflow.xml 文件,内容如下:<workflow-app xmlns="uri:oozie:workflow:0.3" name="shell-wf"> <start to="shell-node"/> <action name="shell-node"> <shell xmlns="uri:oozie:shell-action:0.1"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <exec>echo</exec> <argument>**** first-hello oozie *****</argument> </shell> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message> </kill> <end name="end"/> </workflow-app>在CDH中进入hue,在 HDFS 中创建文件 workflow.xml:
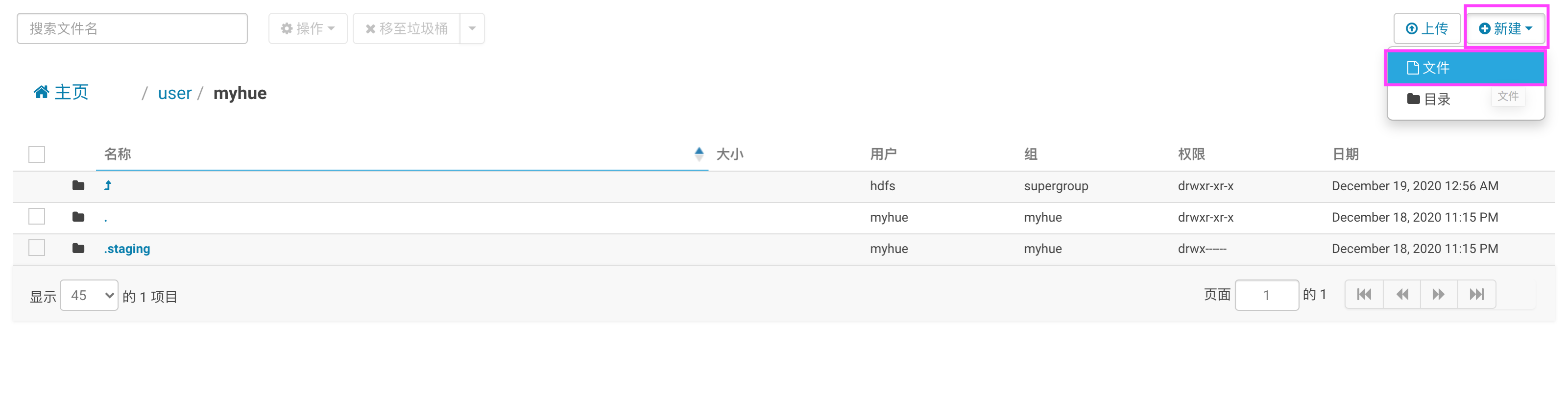
打开文件编辑器,将以上内容写入 workflow.xml 中,点击保存:
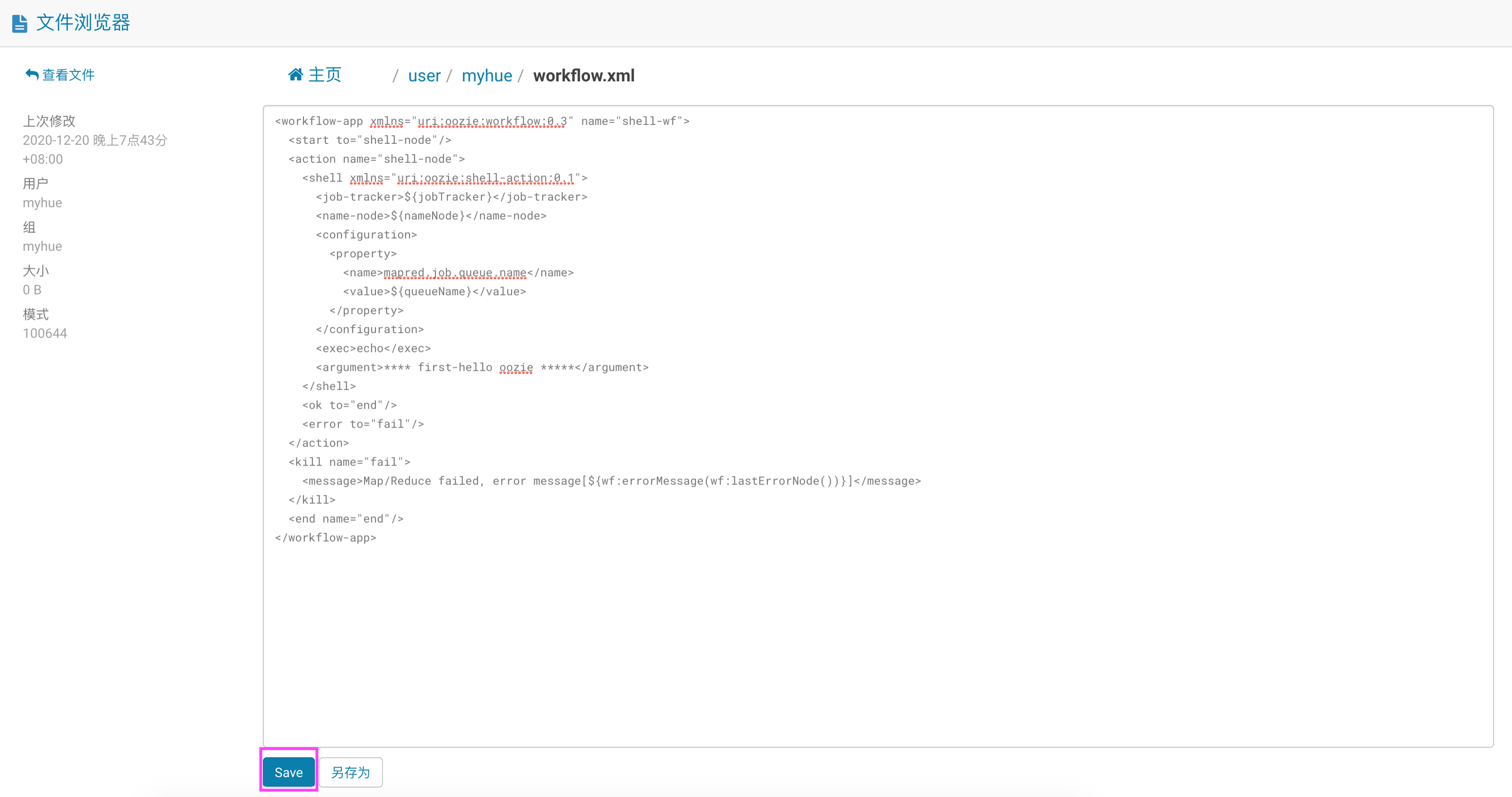
在任意节点上,选择一个节点当做提交 oozie 任务的客户端,创建 job.properties 文件,写入以下内容:
nameNode=hdfs://cm-s1:8020
jobTracker=cm-s1:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/myhue
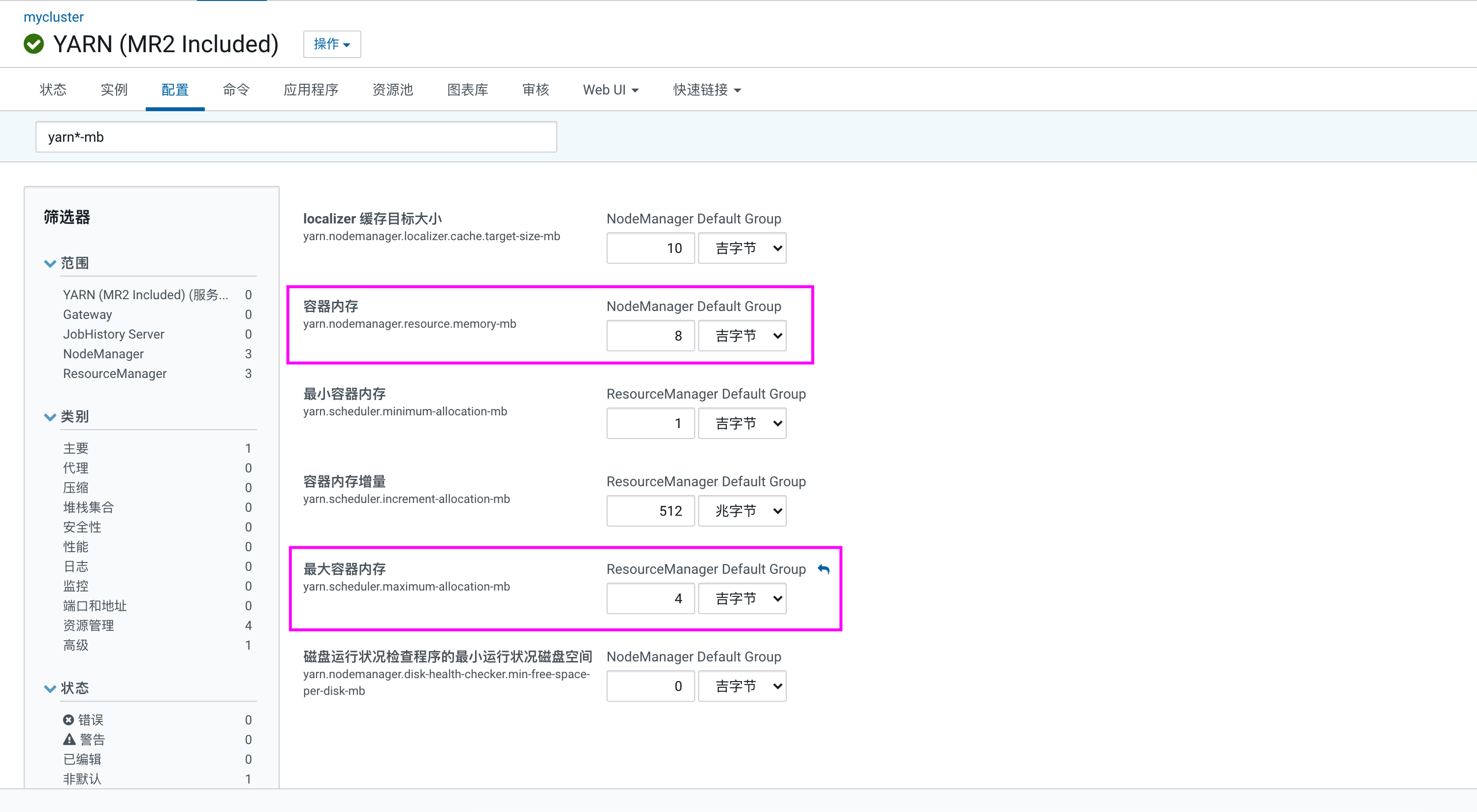
提交oozie任务后会自动转换成MapReduce任务执行,这个时候需要Yarn资源调度。默认在Hadoop2.x版本中默认Yarn每个NodeManager节点分配资源为8core和8G,内存配置为 “yarn.nodemanager.resource.memory-mb” 代表当前NodeManager可以使用的内存总量。每个container启动默认可以使用最大的内存量为 “yarn.scheduler.maximum-allocation-mb”,默认为8G。
在Hadoop3.x版本之后,Yarn NodeManager节点默认分配的资源为1G和4Core。这里oozie任务需要的默认资源是2G和1Core,所以这里需要在Yarn中调大每台NodeManager的内存资源,在Yarn 配置中找到配置项 “yarn.nodemanager.resource.memory-mb(表示该节点上YARN可使用的物理内存总量)” 调节到至少2G以上,同时需要调大每个Container可以使用的最大内存,将 “yarn.scheduler.maximum-allocation-mb(每个Container可申请的最多物理内存量)” 调节到至少2G以上,但是应小于 “yarn.nodemanager.resource.memory-mb” 参数。配置如下:
之后,需要重新启动Yarn集群即可。配置完成后,在当前客户端执行提交如下oozie的命令,可以看到返回了一个jobid,可以根据这个jobId,停止任务或者查看任务执行情况。
[hdfs@cm-s1 ~]# oozie job -oozie http://cm-s1:11000/oozie/ -config job.properties -run
...
job: 0000001-201220195901543-oozie-oozi-W
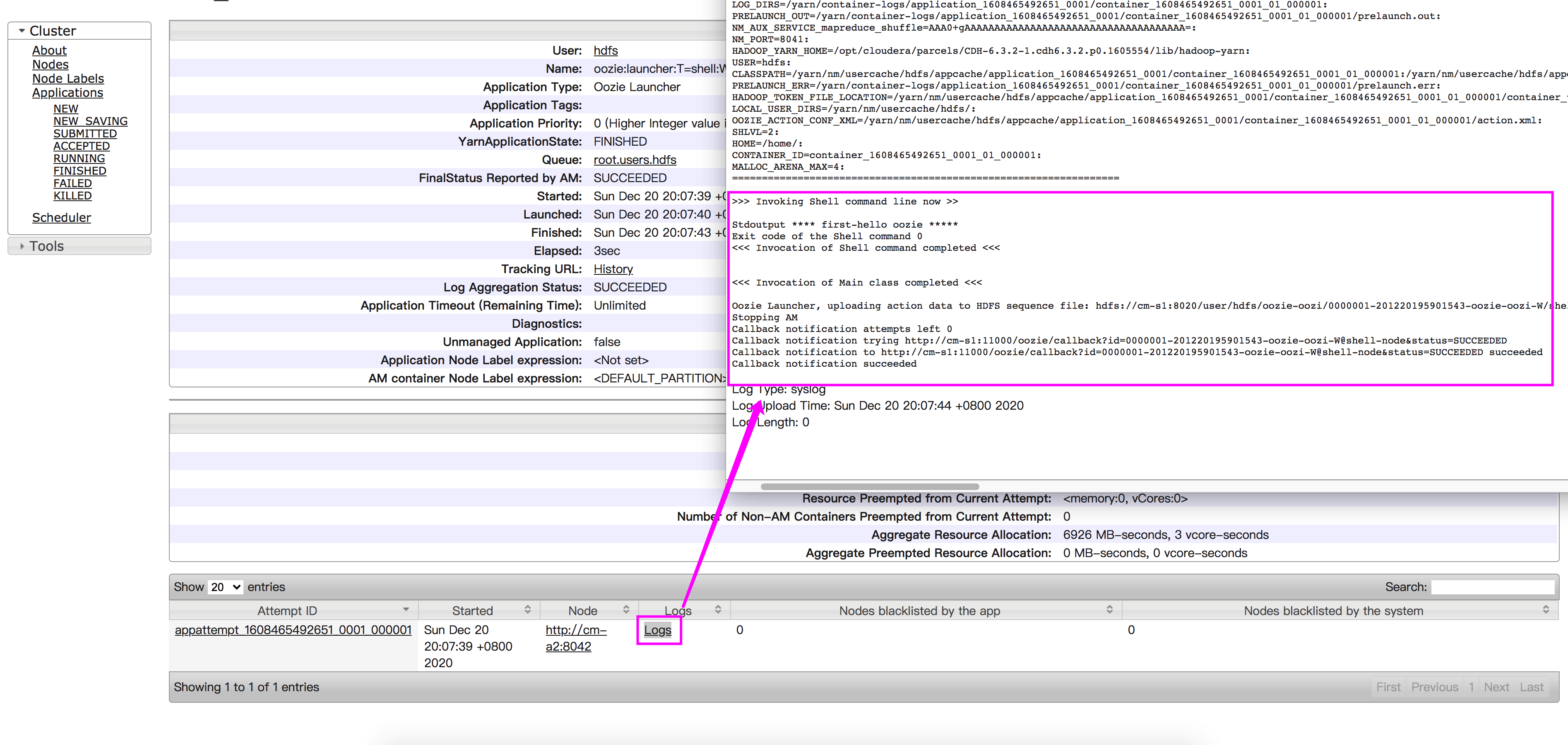
启动任务之后,可以在oozie的webui页面中看到如下结果:

可以查看到分别使用hdfs用户和root用户提交的任务会因权限的不同而出现不同的结果,root用户没有权限访问workflow.xml文件而被中止任务,其实只需要myhue用户就够了,没必要启用超级用户hdfs,这里只是为了方便。
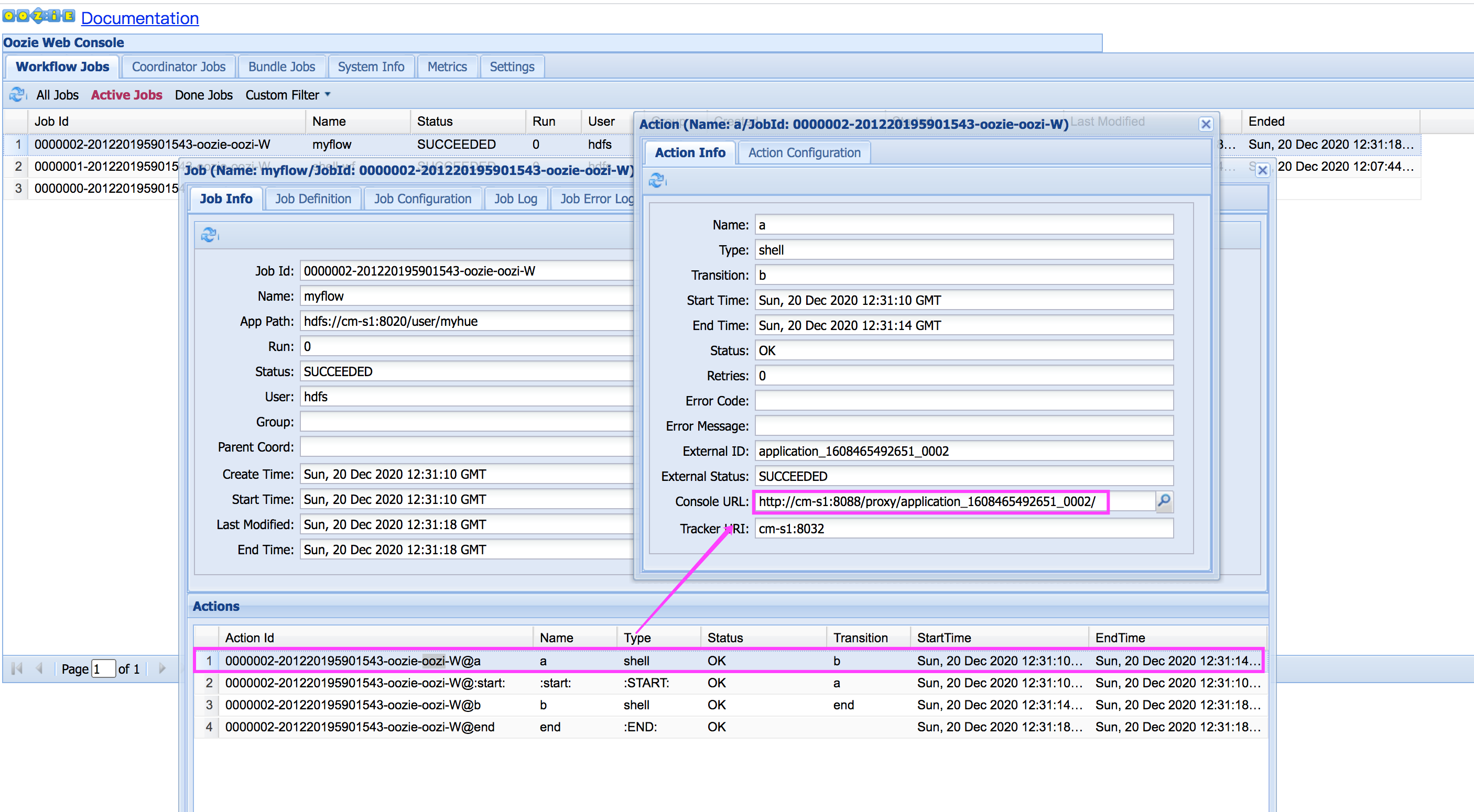
继续点击任务流中的任务找到对应的console url,在浏览器中输入查看结果:

- Oozie 提交含有多个任务的任务流
通过 hue 可以创建 workflow.xml 文件写入以下命令,执行任务a 和任务b:
<workflow-app xmlns="uri:oozie:workflow:0.3" name="myflow">
<start to="a"/>
<action name="a">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>echo</exec>
<argument>**** first-hello oozie *****</argument>
</shell>
<ok to="b"/>
<error to="fail"/>
</action>
<action name="b">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>echo</exec>
<argument>**** second-i am second *****</argument>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
在任意节点,创建文件:job.properties,写入以下内容:
nameNode=hdfs://cm-s1:8020
jobTracker=cm-s1:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/myhue
执行提交oozie任务的命令:
[hdfs@cm-s1 ~]$ oozie job -oozie http://cm-s1:11000/oozie/ -config job.properties -run
job: 0000002-201220195901543-oozie-oozi-W
执行命令之后,进入oozie webui查看任务执行情况:
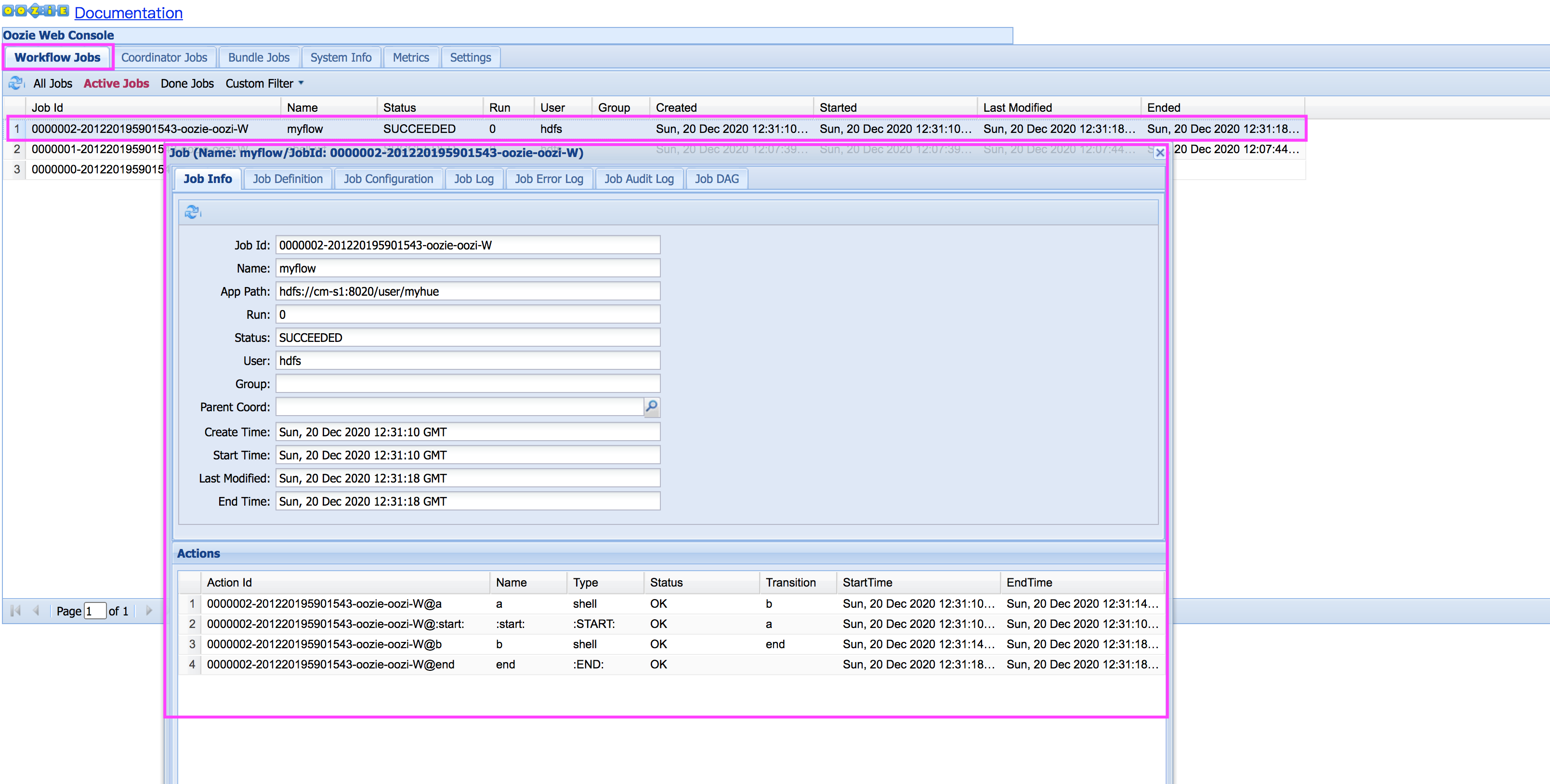
可以点击任务流中的某个任务,查看详细执行信息和登录yarn查看结果。
评论区