


1.1 Kubernetes 日志简介
应用和系统日志可以帮助我们了解在一个集群内部到底发生了什么。当调试问题以及监控集群活动的时候日志是非常有帮助的信息。对于容器应用,默认情况下是将日志信息输出到 stdout 和 stderr 中,同时会将日志信息输出到宿主机上的一个 JSON 文件中,通过命令 docker logs 或是 kubelet logs 就可以查看到对应的日志信息。
但是只使用这种基本的日志输出是没有办法记录完整的日志信息,比如容器崩溃、Pod 驱逐、Node 挂掉等情况出现时,日志信息也就随之消失了。所以我们希望日志可以独立于容器、Pod、Node 节点的生命周期,也就是完全独立于 Kubernetes 系统,这种方式被称为 cluster-level-logging。在 Kubernetes 系统的没有提供现成的解决方案,我们可以借由现在社区已经成熟的一些方案来实现单独的日志存储、分析、查询功能。
1.2 在 Pod 中处理日志(pod-level-logging)
Pod 是 kubernetes 系统最基本的资源对象,所以查看 Pod 的日志是在集群中查看日志最基本的方式,通过 kubelet logs 命令就可以快速查看一个容器的日志信息。
这里部署一个简单的 Pod,这个 Pod 会每隔一秒钟输出当前的时间到 stdout 中。新建 counter.yaml 文件,并向其中写入如下内容:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
执行创建:
$ kubectl create -f counter.yaml -n user-test
pod/counter created
使用 kubelet logs 命令就可以查看日志信息,如下所示:
$ kubectl logs counter -n user-test
0: Sun Nov 22 14:45:58 UTC 2020
1: Sun Nov 22 14:45:59 UTC 2020
2: Sun Nov 22 14:46:00 UTC 2020
3: Sun Nov 22 14:46:01 UTC 2020
...
使用这种方式的好处在于当 Pod 数量很少时,直接通过命令就可以快速获取到日志信息。缺点在于当 Pod 删除时,对应的日志信息也会全部被删除。
1.3 在 Node 中处理日志(node-level-logging)
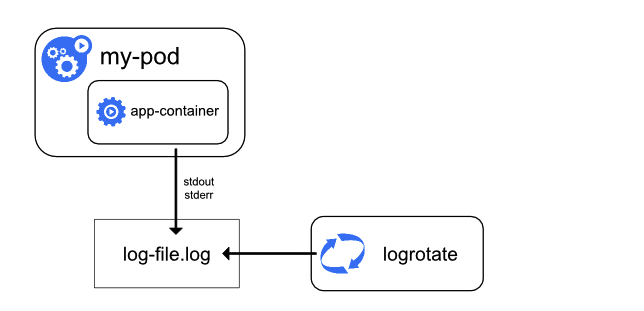
容器输出到 stdout 和 stderr 中的内容会被容器引擎重定向到其它地方。比如:容器引擎会重定向这两个数据流以 JSON 格式写入到 Node 本地的日志文件中。
比如前面的 counter Pod 在 Node 节点上的日志存储位置为 /var/log/containers。可以进行查看:
# 查看 counter Pod 所在节点
$ kubectl get pods -o wide -n user-test
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
counter 1/1 Running 0 2m25s 10.20.177.107 kubesphere03 <none> <none>
# 进入 kubesphere03 节点
$ cd /var/log/containers/
$ ls |grep counter
counter_user-test_count-d00abd39d7b3c843c3de86b84b020be3ac9bc805a120b1b620e870b094109729.log
$ ls -l counter_user-test_count-d00abd39d7b3c843c3de86b84b020be3ac9bc805a120b1b620e870b094109729.log
lrwxrwxrwx 1 root root 80 11月 24 09:19 counter_user-test_count-d00abd39d7b3c843c3de86b84b020be3ac9bc805a120b1b620e870b094109729.log -> /var/log/pods/user-test_counter_8af2174f-df1c-4a7f-bf20-69f76a3d2215/count/0.log
$ tail -f counter_user-test_count-d00abd39d7b3c843c3de86b84b020be3ac9bc805a120b1b620e870b094109729.log
{"log":"284: Tue Nov 24 01:24:10 UTC 2020\n","stream":"stdout","time":"2020-11-24T01:24:10.516774946Z"}
{"log":"285: Tue Nov 24 01:24:11 UTC 2020\n","stream":"stdout","time":"2020-11-24T01:24:11.517832392Z"}
{"log":"286: Tue Nov 24 01:24:12 UTC 2020\n","stream":"stdout","time":"2020-11-24T01:24:12.51886268Z"}
{"log":"287: Tue Nov 24 01:24:13 UTC 2020\n","stream":"stdout","time":"2020-11-24T01:24:13.520058026Z"}
{"log":"288: Tue Nov 24 01:24:14 UTC 2020\n","stream":"stdout","time":"2020-11-24T01:24:14.521043982Z"}
...
需要注意的是,由于持续向 JSON 文件中写入日志,时间一长这个文件将会变得非常大,这个时候可以考虑日志轮换。在部署的时候设置脚本将日志数据切分到多个文件中,可以一天执行一次或当数据增长到某个固定大小(比如 10M)时执行。
当运行 kubelet logs 命令时,在 Node 节点上的 kubelet 会处理请求、直接从日志文件中读取内容并返回响应。如果是执行了轮换,就会读取最新日志文件中的数据。
Node 级别的日志相比于 Pod 级别的日志更加具有可持续性。如果一个 Pod 被重启,它之前的日志会被保留在 Node 上;但是如果 Pod 被驱逐,它之前的所有日志数据在 Node 上将被删除。
1.4 在每个 Node 节点上运行一个 agent 收集日志
“在每个节点上运行一个 agent 收集日志”的原理图如下所示:
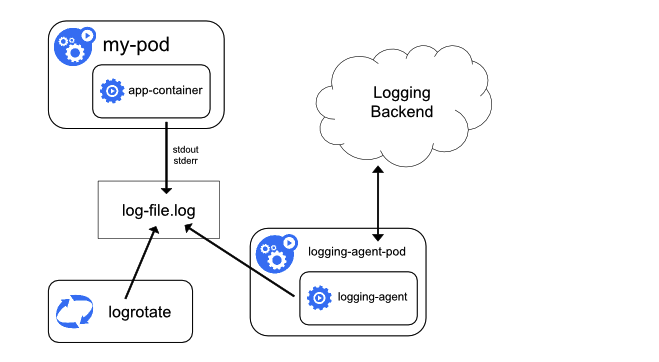
这里的关键点在于每个节点上都运行了一个 logging-agent 容器,这个容器可以读取 Node 节点上的日志文件目录,然后将日志信息转发给存储后端。所以 logging-agent 容器一般以 DaemonSet 的方式进行部署。
这种方式是 kubernetes 日志收集系统最常用的一种,经常采用的技术栈为 EFK(Elasticsearch + Fluentd + Kibana),其中 Fluentd 就是运行在每个节点上的 Agent,然后将收集到的日志转发给后端存储 Elasticsearch。
使用这种方式收集日志的好处在于:只需要在每个节点上运行一个代理容器,不需要对节点上的其它容器进行修改,耦合度低。
但是这种方式要求应用程序的日志只能输出到 stdout 和 stderr 中,对于自定义日志输出路径的应用是不适用的。
1.5 在每个 Pod 中运行 sidecar 容器收集日志
在每个 Pod 中运行一个 sidecar 容器收集日志的这种方式就是为了弥补上一种方式的不足,即:不能自定义日志输出路径。
运行 sidecar 容器收集日志在实际应用场景下又分为两种具体的方式:
- sidecar 容器把日志文件重新输出到 stdout/stderr 中。
- sidecar 容器直接把日志文件发送到远端存储中。
sidecar 容器把日志文件重新输出到 stdout/stderr 中
它的原理图如下所示:
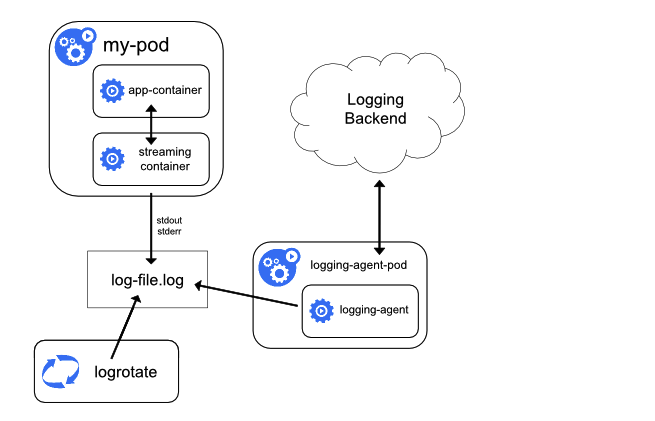
大家可以看到图中,在 my-pod 中运行了两个容器分别是 app-container 和 streaming container。app-container 容器自定义了日志文件输出路径;streaming container 容器的作用就是一个简单的代理,首先从 app-container 容器的自定义日志文件路径中获取日志数据,然后再输出到 stdout 和 stderr 中;最后使用前面介绍的方式,在 Node 上运行代理容器收集整个节点的日志数据。
比如下面这个例子,在一个 Pod 中运行了一个容器,这个容器会以不同的形式分别向 /var/log/1.log 和 /var/log/2.log 文件中写入数据。新建 counter-pod.yaml 文件并向其中写入如下内容:
apiVersion: v1
kind: Pod
metadata:
name: counter-pod
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
执行创建:
$ kubectl create -f counter-pod.yaml -n user-test
pod/counter-pod created
尝试直接查看日志:
$ kubectl logs counter-pod -n user-test
并没有日志输出。
在这种情况下如果想要获取 counter-pod 的日志,可以在 Pod 中再部署两个 sidecar 容器,分别读取 /var/log/1.log 和 /var/log/2.log 文件并输出到 stdout 和 stderr 中。新建 counter-pod-streaming-sidecar.yaml 文件并向其中写入如下内容:
apiVersion: v1
kind: Pod
metadata:
name: counter-pod-streaming-sidecar
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, "tail -n+1 -f /var/log/1.log"]
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, "tail -n+1 -f /var/log/2.log"]
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
执行创建:
$ kubectl create -f counter-pod-streaming-sidecar.yaml -n user-test
pod/counter-pod-streaming-sidecar created
查看日志:
$ kubectl logs counter-pod-streaming-sidecar -c count-log-1 -n user-test
0: Tue Nov 24 01:39:31 UTC 2020
1: Tue Nov 24 01:39:32 UTC 2020
2: Tue Nov 24 01:39:33 UTC 2020
3: Tue Nov 24 01:39:34 UTC 2020
4: Tue Nov 24 01:39:35 UTC 2020
5: Tue Nov 24 01:39:36 UTC 2020
6: Tue Nov 24 01:39:37 UTC 2020
$ kubectl logs counter-pod-streaming-sidecar -c count-log-2 -n user-test
Tue Nov 24 01:39:31 UTC 2020 INFO 0
Tue Nov 24 01:39:32 UTC 2020 INFO 1
Tue Nov 24 01:39:33 UTC 2020 INFO 2
Tue Nov 24 01:39:34 UTC 2020 INFO 3
Tue Nov 24 01:39:35 UTC 2020 INFO 4
Tue Nov 24 01:39:36 UTC 2020 INFO 5
Tue Nov 24 01:39:37 UTC 2020 INFO 6
Tue Nov 24 01:39:38 UTC 2020 INFO 7
Tue Nov 24 01:39:39 UTC 2020 INFO 8
Tue Nov 24 01:39:40 UTC 2020 INFO 9
Tue Nov 24 01:39:41 UTC 2020 INFO 10
sidecar 和主容器之间是共享卷的,性能损耗不算大,只是会多消耗一些 CPU 和内存。但是使用这种方式,相当于在 Node 节点上存在了两份相同的日志文件,一份是应用日志重定向文件,另一份是 sidecar 在节点上的输出的日志文件,这对于磁盘浪费还是比较大。所以只在特殊情况下才使用这种方式采集日志。
sidecar 容器直接把日志文件发送到远端存储中
它的原理图如下所示:
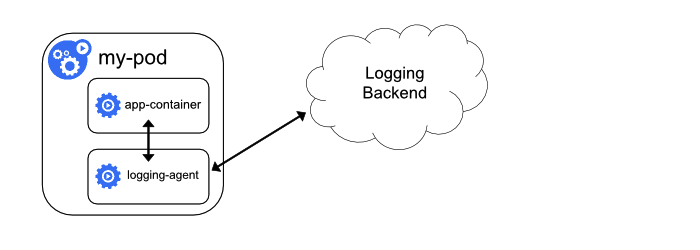
在图中可以看到:logging-agent 与主容器运行在同一个 Pod 中,然后直接将收集到的日志数据推送到采集后端。
比如同样是上一节中的 count 容器,可以在相同的 Pod 中再创建一个 fluentd 容器作为 sidecar,fluentd 容器采集 count 容器的日志数据(1.log 和 2.log)并写入到 /var/log/fluent/access 文件中(在实际应用中可以配置发送给 Elasticsearch)。
首先将 fluentd 的配置信息存储到 ConfigMap 中,新建 fluentd-sidecar-config.yaml 文件并向其中写入如下内容:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type file
path /var/log/fluent/access
</match>
执行创建:
$ kubectl create -f fluentd-sidecar-config.yaml -n user-test
configmap/fluentd-config created
接下来创建 Pod,新建 counter-pod-agent-sidecar.yaml 文件并向其中写入如下内容:
apiVersion: v1
kind: Pod
metadata:
name: counter-pod-agent-sidecar
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: broadinstitute/fluentd-gcp
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
执行创建:
$ kubectl create -f counter-pod-agent-sidecar.yaml -n user-test
pod/counter-pod-agent-sidecar created
$ kubectl get pods -o wide -n user-test
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
counter-pod-agent-sidecar 2/2 Running 0 19s 10.20.177.116 kubesphere03 <none> <none>
现在来查看 count-agent 容器是否成功读取到日志数据:
$ kubectl exec -n user-test -it counter-pod-agent-sidecar sh
Defaulting container name to count.
Use 'kubectl describe pod/counter-pod-agent-sidecar -n user-test' to see all of the containers in this pod.
/ # cd /var/log
/var/log # ls
1.log 1.log.pos 2.log 2.log.pos fluent journal
/var/log # cd fluent/
/var/log/fluent # ls
access.20201124.b5b4d08637c242e05
/var/log/fluent # tail -f access.20201124.b5b4d08637c242e05
2020-11-24T01:51:50+00:00 count.format1 {"message":"135: Tue Nov 24 01:51:50 UTC 2020"}
2020-11-24T01:51:50+00:00 count.format2 {"message":"Tue Nov 24 01:51:50 UTC 2020 INFO 135"}
2020-11-24T01:51:51+00:00 count.format1 {"message":"136: Tue Nov 24 01:51:51 UTC 2020"}
2020-11-24T01:51:51+00:00 count.format2 {"message":"Tue Nov 24 01:51:51 UTC 2020 INFO 136"}
2020-11-24T01:51:52+00:00 count.format1 {"message":"137: Tue Nov 24 01:51:52 UTC 2020"}
2020-11-24T01:51:52+00:00 count.format2 {"message":"Tue Nov 24 01:51:52 UTC 2020 INFO 137"}
2020-11-24T01:51:53+00:00 count.format1 {"message":"138: Tue Nov 24 01:51:53 UTC 2020"}
2020-11-24T01:51:53+00:00 count.format2 {"message":"Tue Nov 24 01:51:53 UTC 2020 INFO 138"}
...
使用这种方式对于容器应用就是强耦合,在部署的时候就需要手动进行设置;同时也会造成巨大的资源消耗;而且也无法再使用 kubelet logs 命令查看目标容器的日志信息。
1.6 直接在应用程序中将日志信息推送到采集后端
它的原理图如下所示:
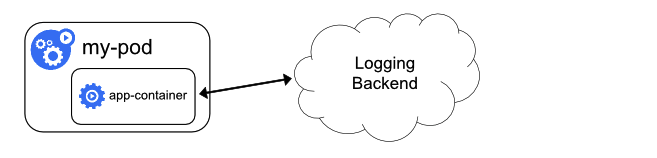
也可以直接在应用程序中设置将日志信息推送到日志后端,但是这个需要修改代码,集群层面无需操作。
综合分析上述三种类型的日志采集方式,最推荐的还是使用第一种方式“在每个节点上运行一个 agent 收集日志”。
2.1 EFK 简介
在集群中,应用往往涉及到多个组件,这些组件对应 Pod 所在的 Node 节点和副本数量本身也在发生着变化,通过搭建统一的日志管理系统,可以对日志进行统一收集和检索,简化运维工作。
Kubernetes 官方推荐的日志收集方案是 EFK 技术栈(Elasticsearch + Fluentd + Kibana)。
在容器中输出到控制台的日志,都会保存在 /var/lib/docker/containers 目录下,命名方式为 *-json.log,这样就方便日志采集和后续处理。
Elasticsearch
Elasticsearch 是一个实时、分布式的可扩展的搜索引擎,可以进行全文、结构化搜索,通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Fluentd
Fluentd 是一个流行的开源数据收集器,可以在 Kubernetes 集群所有节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
Kibana
Kibana 通常与 Elasticsearch 共同部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
那么整个 EFK 日志收集系统的架构如下所示:
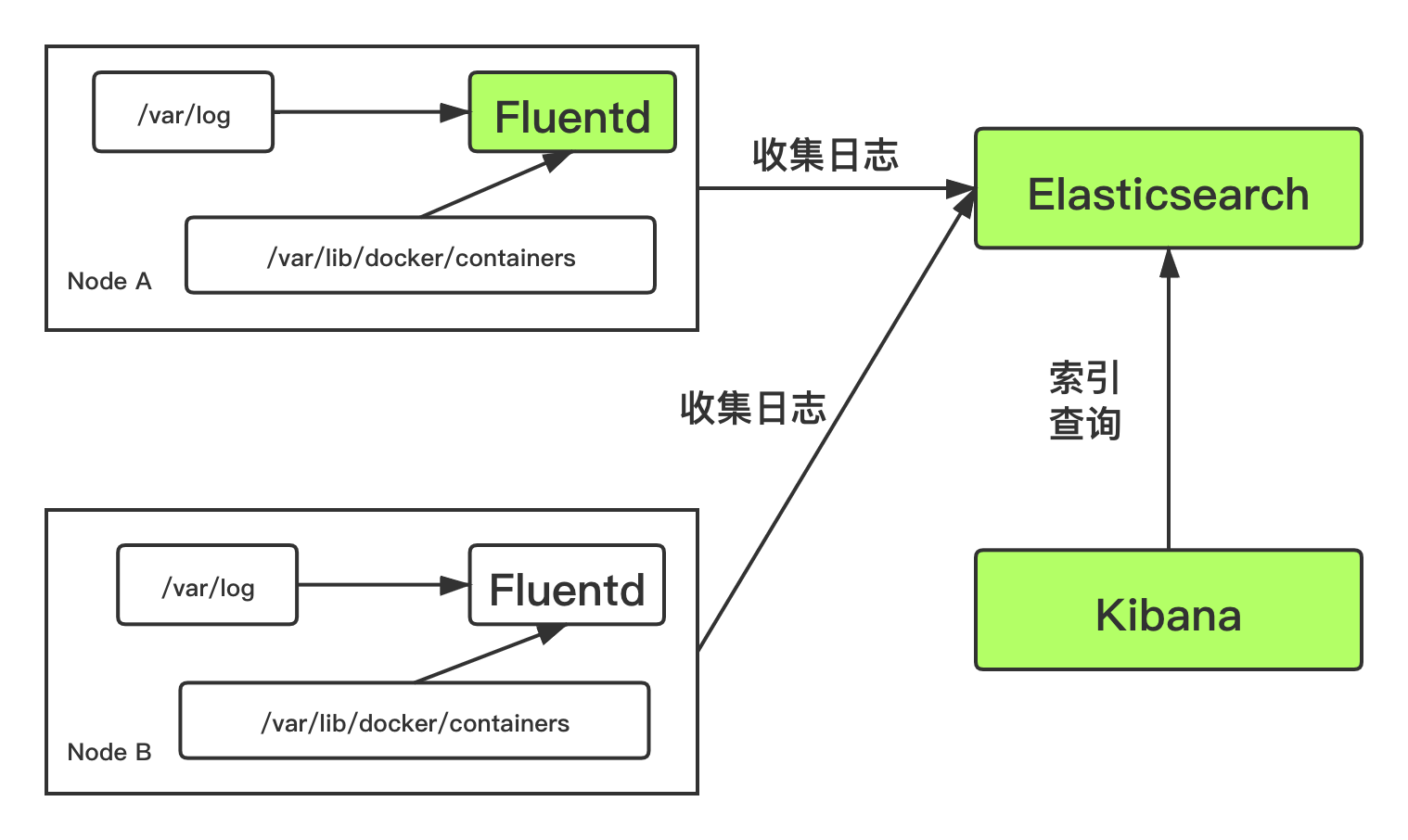
在每个 Node 节点上都运行了一个 Fluentd 容器,用于采集该节点 /var/log 和 /var/lib/docker/containers 两个目录下的日志文件,然后将采集到的数据汇总到 Elasticsearch 集群中,然后通过 Kibana 进行日志索引与查询、包括图形化界面展示。
2.2 使用 EFK 搭建日志收集系统
这里使用纯净的k8s集群,各节点如下:
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ks.m1 Ready master 78m v1.17.9 192.168.1.41 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://18.9.9
ks.m2 Ready master 77m v1.17.9 192.168.1.42 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://18.9.9
ks.m3 Ready master 77m v1.17.9 192.168.1.43 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://18.9.9
ks.s1 Ready worker 77m v1.17.9 192.168.1.44 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://18.9.9
ks.s2 Ready worker 77m v1.17.9 192.168.1.45 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://18.9.9
对于 Elasticsearch 使用 StatefulSet 部署有状态服务,同时创建对应的 ClusterIP Service 对外开放 9200 端口;而 Fluentd 将大量的配置都写入了 ConfigMap 中,使用 DaemonSet 进行创建;最后使用 Deployment 创建 Kibana,创建对应的 service 对外开放 5601 端口。所有的资源对象都是在 kube-system 命名空间下创建。
部署 Elasticsearch
部署 Elasticsearch 涉及到两个文件:es-service.yaml 和 es-statefulset.yaml。
在 es-service.yaml 文件中,创建了名为 elasticsearch-logging 的 ClusterIP Service,开放 9200 端口(也是 Elasticsearch 默认的端口)。
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Elasticsearch"
spec:
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch-logging
在 es-statefulset.yaml 文件中,创建了名为 elasticsearch-logging 的 ServiceAccount,创建对应的 ClusterRole 和 ClusterRoleBinding,使用 StatefulSet 部署 elasticsearch:v7.3.2,并使用 emptyDir 类型的存储卷(测试环境未做持久化),并且初始化容器的 vm.max_map_count 值为 262144。
# RBAC authn and authz
apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "services"
- "namespaces"
- "endpoints"
verbs:
- "get"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: kube-system
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: elasticsearch-logging
namespace: kube-system
apiGroup: ""
roleRef:
kind: ClusterRole
name: elasticsearch-logging
apiGroup: ""
---
# Elasticsearch deployment itself
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch-logging
namespace: kube-system
labels:
k8s-app: elasticsearch-logging
version: v7.3.2
addonmanager.kubernetes.io/mode: Reconcile
spec:
serviceName: elasticsearch-logging
replicas: 2
selector:
matchLabels:
k8s-app: elasticsearch-logging
version: v7.3.2
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v7.3.2
spec:
serviceAccountName: elasticsearch-logging
containers:
- image: elasticsearch:7.3.2
name: elasticsearch-logging
imagePullPolicy: Always
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
memory: 3Gi
requests:
cpu: 100m
memory: 3Gi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: elasticsearch-logging
mountPath: /data
env:
- name: "NAMESPACE"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumes:
- name: elasticsearch-logging
emptyDir: {}
# Elasticsearch requires vm.max_map_count to be at least 262144.
# If your OS already sets up this number to a higher value, feel free
# to remove this init container.
initContainers:
- image: alpine:3.6
command: ["/sbin/sysctl", "-w", "vm.max_map_count=262144"]
name: elasticsearch-logging-init
securityContext:
privileged: true
执行创建 Elasticsearch:
$ kubectl create -f es-service.yaml
service/elasticsearch-logging created
$ kubectl create -f es-statefulset.yaml
serviceaccount/elasticsearch-logging created
clusterrole.rbac.authorization.k8s.io/elasticsearch-logging created
clusterrolebinding.rbac.authorization.k8s.io/elasticsearch-logging created
statefulset.apps/elasticsearch-logging created
评论区