


5.1 kube-scheduler 简介
kube-scheduler 通过监听 kube-apiserver,获取未调度的 Pod 列表,通过调度算法计算出分配给 Pod 的 Node,并将 Node 信息与 Pod 进行绑定(Bind),结果存储在 etcd 中。而根据调度结果执行 Pod 的创建操作是由 Node 上的 kubelet 执行的。
kube-scheduler 作为 Master 上的核心模块,我们可以把它当做一个黑盒来处理,黑盒的输入为待调度的 Pod 和全部计算节点(Node)的信息,经过黑盒内部的调度算法和策略处理,输出为最优节点,然后由 kubelet 执行将 Pod 调度到对应 Node 的具体操作,kubelet 获取对应的 Pod 清单,下载镜像并启动容器。
kube-scheduler 职责及调度流程
kube-scheduler 的职责主要有以下 3 个:
- 集群高可用
kube-scheduler 可以设置 leader-elect 启动参数,这样会通过 etcd 进行节点选主。kube-scheduler 和 kube-controller-manager 都使用了一主多从的高可用方案。简单理解的话是这样的:kube-scheduler 启动时,会在 etcd 中创建 endpoint,endpoint 的信息中记录了当前的 leader 节点信息,以及上次更新时间。leader 节点会定期更新 endpoint 的信息,维护自己的 leader 身份,每个从节点的服务都会定期检查 endpoint 的信息,如果 endpoint 的信息在规定的时间范围内没有更新,从节点将会尝试更新自己的 leader 节点。
- 调度资源监听
通过 Watch 机制监听 kube-apiserver 上资源(Pod 和 Node)的变化。
kube-apiserver 给其它的组件(比如:kubelet、kube-controller-manager、kube-scheduler)等提供了一套 Watch 机制用于监控各种资源的变化,类似于消息中间件的发布-订阅模式(Push),这样 kube-apiserver 可以主动通知这些组件。
kube-apiserver 初始化时,会建立对 etcd 的连接并 watch etcd。当 kube-scheduler 客户端调用 Watch API 时,kube-apiserver 内部会建立一个 WatchServer,WatchServer 会从 etcd 中获取资源的 Watch event,Watch event 经过加工过滤后就会发送给客户端,Watch API 本质上是一个 GET 请求,通常有两种实现模式:通过 websocket 协议发送;或是通过 Transfer-Encoding=chunked 方式建立长连接。
- 调度节点分配
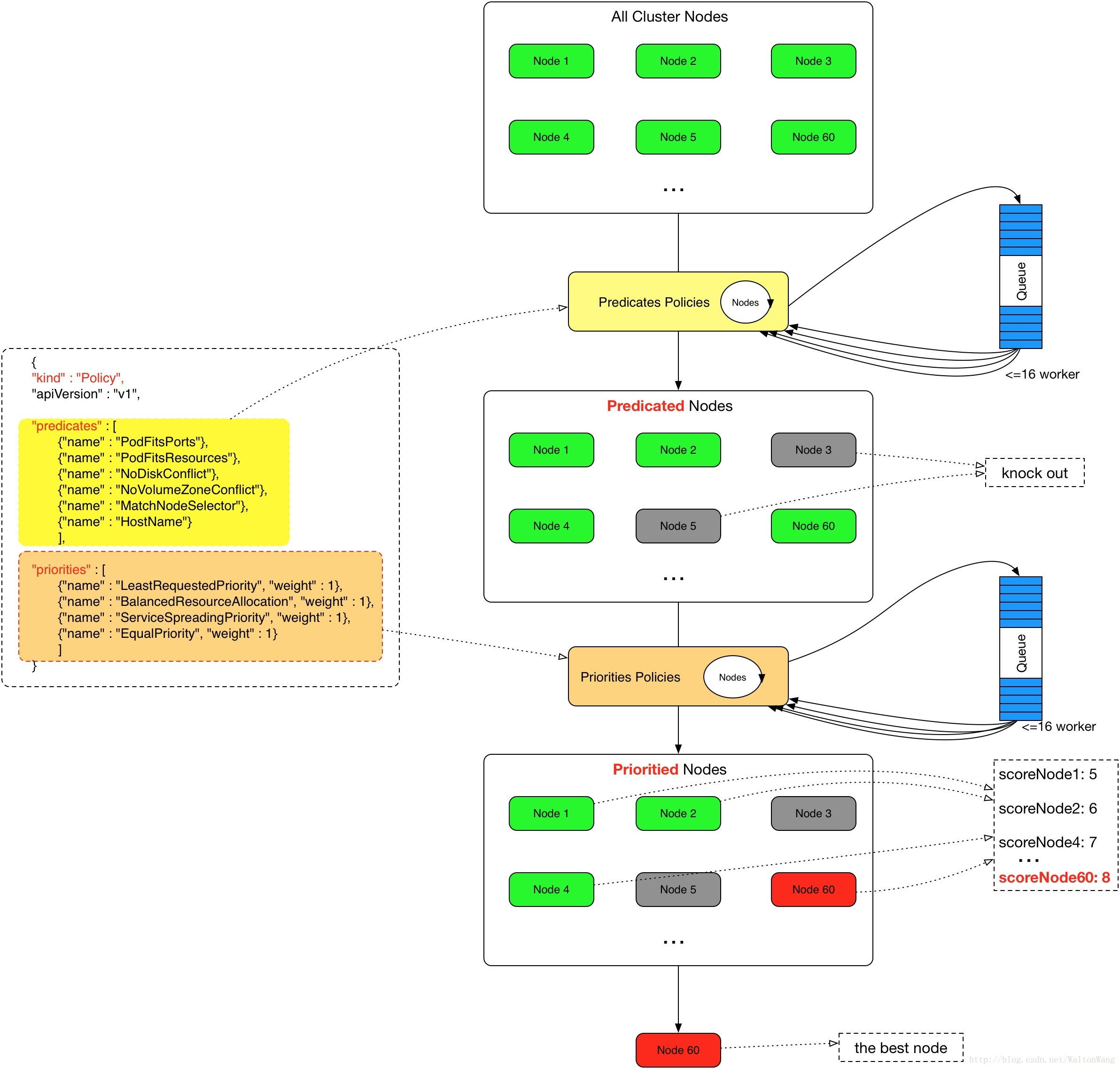
这个职责也是我们本节点将会重点介绍的部分。调度节点分配分为两个环节:预选(Predicates)与优选 (Priorites)。调度资源监听也是为了这个环节提供数据输入。
- 预选:遍历所有目标 Node,根据配置的预选策略 Predicates Policies 过滤掉不符合策略的 Node,剩下符合要求的候选节点。预选的输出将会作为优选的输入。预选策略默认使用的是 DefaultProvider 中定义的 default predicates policies 集合。
- 优选:根据配置的优选策略 Priorites Policies,为前一步过滤后的 Node 进行打分排名,得分最高的 Node 将作为最适合的 Node,该 Pod 将绑定(Bind)到最适合的 Node 上。如果打分排名后,有多个 Node 并列得分最高,kube-scheduler 会从中随机选取一个 Node 作为目标 Node。优选策略默认使用的是 DefaultProvider 中定义的 default priorites policies 集合。
kube-scheduler 调度节点分配需要考虑的问题较多,有:
- 公平:如何保证每个 Node 都能够分配资源
- 资源高效利用:集群所有资源能够被最大化使用
- 效率:调度性能高,能够尽快对大批量的 Pod 完成调度工作
- 灵活:允许用户自定义调度逻辑
kube-scheduler 官方流程图如下所示:
For given pod:
+---------------------------------------------+
| Schedulable nodes: |
| |
| +--------+ +--------+ +--------+ |
| | node 1 | | node 2 | | node 3 | |
| +--------+ +--------+ +--------+ |
| |
+-------------------+-------------------------+
|
|
v
+-------------------+-------------------------+
Pred. filters: node 3 doesn't have enough resource
+-------------------+-------------------------+
|
|
v
+-------------------+-------------------------+
| remaining nodes: |
| +--------+ +--------+ |
| | node 1 | | node 2 | |
| +--------+ +--------+ |
| |
+-------------------+-------------------------+
|
|
v
+-------------------+-------------------------+
Priority function: node 1: p=2
node 2: p=5
+-------------------+-------------------------+
|
|
v
select max{node priority} = node 2
5.2 常用参数
kube-scheduler 在启动的时候也可以指定一些参数,列表如下:
| 参数 | 含义 | 默认值 |
|---|---|---|
| --adress | 监听地址 | "0.0.0.0" |
| --port | 调度器监听的端口 | 10251 |
| --algorithm-provider | 提供调度算法的对象 | "DefaultProvider" |
| --master | API Server 的 HTTP 地址 | / |
| --profiling | 是否开启 profiling,开启后可以在host:port/debug/pprof访问 profile 信息 | true |
| --scheduler-name | 调度器名称,用来唯一确定该调度器 | "default-shcheduler" |
| --kube-api-burst | 和 API Server 通信时的最大 burst 值 | 100 |
| --kube-api-qps | 和 API Server 通信时的 QPS 值 | 50 |
| --log_dir | 日志保存的目录 | / |
| --policy-config-file | json 配置文件,用来指定调度器的 Predicates 和 Priorites 策略 | / |
关于自定义策略的 JSON 文件的格式示例如下:
{
"kind": "Policy",
"apiVersion": "v1",
"predicates":
[
{ "name": "PodFitsHostPorts" },
{ "name": "PodFitsResources" },
{ "name": "NoDiskConflict" },
{ "name": "NoVolumeZoneConflict" },
{ "name": "MatchNodeSelector" },
{ "name": "HostName" },
],
"priorities":
[
{ "name": "LeastRequestedPriority", "weight": 1 },
{ "name": "BalancedResourceAllocation", "weight": 1 },
{ "name": "ServiceSpreadingPriority", "weight": 1 },
{ "name": "EqualPriority", "weight": 1 },
],
"hardPodAffinitySymmetricWeight": 10,
"alwaysCheckAllPredicates": false,
}
5.3 预选策略 (Predicates Policies)
预选策略的主要目的是过滤掉不符合条件的 Node 节点,预选策略大体上可以分为如下 4 类:
- GeneralPredicates:负责最基础的调度策略
- 与 Volume 相关的过滤规则:负责与容器持久化 Volume 相关的调度策略
- 与 Node 相关的过滤规则:负责考察待调度 Pod 是否满足 Node 本身的一些条件
- 与已运行 Pod 相关的过滤规则:负责检查待调度 Pod 与 Node 上已有 Pod 之间的亲和性关系
当开始调度 Pod 时,调度器会同时开启多个协程并发进行 Predicates 过滤,每个协程按照固定的顺序进行过滤,最后返回过滤后可以运行 Pod 的 Node 列表。
- GeneralPredicates
是最基础的调度策略,这个接口也会被其它组件直接调用,比如 kubelet 在启动 Pod 前会再执行一遍 GeneralPredicates 用于二次确认。
它包含的具体策略有:
- PodFitsResources:计算 Node 的 CPU、内存、扩展资源(如 GPU)是否够用
- PodFitsHost:检查 Node 的名字是否跟 Pod 的 spec.nodeName 匹配
- PodFitsHostPorts:检查 Pod 申请的 Node 端口是否冲突
- PodMatchNodeSelector:检查 Node 是否能匹配 Pod 的 nodeSelector 和 nodeAffinity2. 与 Volume 相关的过滤规则
它包含的具体策略有:
- NoDiskConflict:检查 Node 上所有的 Pods 是否与待调度 Pod 的 Volume 有冲突,比如 AWS、GCE 的 Volume 不能被两个 Pod 同时使用
- VolumeZonePredicate:检查 Pod Volume 的 zone 标签是否与节点的 zone 标签匹配,如果 Node 没有 zone 标签就认定为匹配
- MaxPDVolumeCountPredicate:检查 Node 上某种类型的 Volume 是否已经超过指定数目
- CSIMaxVolumeCountPredicate:检查 CSI Volume 相关的限制
- VolumeBindingPredicate:检查 Pod 对应的 Local PV 的 nodeAffinity 字段,是否跟某个 Node 标签相匹配。如果该 Pod PVC 还没有绑定 PV,调度器要检查所有待绑定的 PV,且该 PV 的 nodeAffinity 是否与 Node 标签匹配3. 与 Node 相关的过滤规则
它包含的具体策略有:
- NodeConditionPredicate:检查 Node 是否还未准备好或处于 NodeOutOfDisk、NodeNetworkUnavailable 状态,或者 Node 的 spec.Unschedulable 设置为 true,如果出现以上的情况,该 Node 都无法被调度
- PodTolerateNodeTaints:检查 Node 的 taint(污点)机制,只有当 Pod 的 Toleration 与 Node 的 Taint 匹配时,Pod 才能调度到该 Node 上
- NodeMemoryPressurePredicate:检查 Node 的内存是否不够使用
- NodeDiskPressurePredicate:检查 Node 的磁盘是否不够使用
- NodePIDPressurePredicate:检查 Node 的 PID 是否不够使用4. 与已运行 Pod 相关的过滤规则
它包含的具体策略主要是:PodAffinityPredicate,用于检查待调度 Pod 与 Node 上已有 Pod 之间的亲和性与反亲和性关系。
5.4 优选策略 (Priorites Policies)
通过前面预选策略过滤出来的 Node 列表,会再一次使用优选策略为这些 Node 打分,最终得分最高的 Node 会作为该 Pod 的调度对象。
有多个优选策略就相当于有多个打分函数,那么总得分的计算公式为:总分 = (打分函数 1 * 权重 1) + (打分函数 2 * 权重 2) + ... + (打分函数 3 * 权重 3),打分函数的打分范围为 0 - 10 分,0 表示非常不合适,10 表示非常合适。每个打分函数都可以配置对应的权重,默认权重值为 1,如果某个打分函数特别重要就可以增加该权重值。
常用的优选策略有:
- LeastRequestedPriority:选出空闲资源(CPU & Memory)最多的 Node
- BalancedResourceAllocation:主要用于资源平衡,选出各项资源分配最均衡的 Node,避免出现某些 Node CPU 被大量分配,而 Memory 大量剩余的情况
- SelectorSpreadPriority:为了更好容灾,对属于同一个 Service 或是 RC 的多个 Pod 副本,尽量调度到多个不同的 Node 上
- InterPodAffinityPriority:优先将 Pod 调度到相同的拓扑上(如同一个节点、Rack、Zone 等)
- NodeAffinityPriority:优先调度到匹配 NodeAffinity 的 Node 上
- TaintTolerationPriority:优先调度到匹配 TaintToleration 的 Node 上
- ImageLocalityPriority:优先选择已经存在 Pod 所需 Image 的 Node(已注册但默认未使用)
- MostRequestedPriority:优先选择已经使用过的 Node,适用于 cluster-autoscaler(已注册但默认未使用)
因此kube-scheduler 算法流程图如下所示:
5.5 自定义调度器
除了使用集群自带的调度器,也可以编写自定义的调度器,然后在 Pod YAML 文件中通过参数 spec.schedulername 指定调度器的名称,这样在 Pod 创建时就会使用自定义的调度器而不是集群默认的调度器。
比如:
apiVersion: v1
kind: Pod
metadata:
name: Pod-example
spec:
# 使用自定义调度器 my-scheduler
schedulername: my-scheduler
containers:
- name: nginx
image: nginx
而自定义调度器的实现逻辑依然是:读取 API Server 中 Pod 列表,通过特定算法找到最适合的 Node,然后把调度结果写回到 API Server。
评论区