


6.1 Etcd 数据库概述
Etcd 是 CoreOS 基于 raft 一致性算法协议开发的一款高可用分布式 key-value 存储数据库,可用于服务发现、共享配置以及一致性保障,数据库本身是基于 Go 语言实现。
Etcd 数据库在设计的时候主要考虑了 4 个要素:
- 简单:具有定义良好、面向用户的 API(gRPC)。
- 安全:基于 HTTPS 方式访问。
- 快速:支持并发 10K/s 的写操作。
- 可靠:支持分布式结构,基于 raft 一致性算法。
它的主要功能特点有:
- 基本的 key-value 存储。
- 监听机制。
- key 的过期及续约机制,用于监控和服务发现。
- 原子 CAS 和 CAD,用于分布式锁和 leader 选举。
Etcd v2 和 v3 从本质上来说是共享同一套 raft 协议代码的两个独立应用,这两个版本的接口不同,存储不同,数据之间互相隔离、互不兼容。就是说使用 v2 版本创建的数据只能使用 v2 的 API 接口访问,使用 v3 版本创建的数据只能使用 v3 的 API 接口访问。在 Kubernetes 集群中推荐使用的是 Etcd v3 版本,Etcd v2 版本在 Kubernetes v1.11 中已经被弃用。
6.2 Etcd 工作原理:Raft 协议
Etcd 使用的是 Raft 协议实现的,Raft 是一套通过选取主节点来实现分布式系统一致性的算法。关于 Raft 一致性算法可以参考 raft 一致性算法动画演示。
如下图所示,每个 ETCD 节点都维护了一个状态机,在任意时刻最多存在一个有效的主节点,主节点处理所有来自客户端的写操作,通过 Raft 协议保证写操作对状态机的改动会可靠的同步到其它节点。
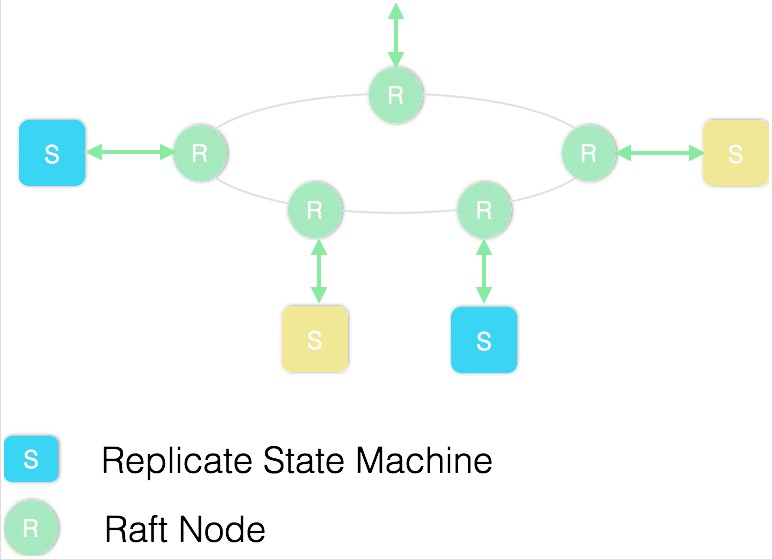
Raft 协议主要分为 3 个部分:选主、日志复制、安全性。
选主
Raft 协议是用于维护一组服务节点数据一致性的协议。这一组服务节点构成一个集群,并且有一个主节点来对外提供服务。当集群初始化或主节点挂掉后,面临一个选主问题。集群中每个节点,任意时刻处于 Leader、Follower、Candidate(候选) 这三个角色之一,选举特点如下:
- 当集群初始化的时候,每个节点都是 Follower 角色;
- 集群中存在最多一个有效的主节点,主节点通过 heartbeat 与其它节点同步数据;
- 当 Follower 在一定时间内没有收到来自主节点的 heartbeat,会将自己的角色改变成为 Candidate,并发起一次选主投票;当收到集群中过半数节点(包括自己在内)的接收投票后,选举成功,该节点成为 Leader,开始接收保存 Client 的数据并向其它的 Follower 节点同步日志。如果票数不足半数或超时则选举失败。如果本轮没有选举出主节点,将进行下一轮选举。
- Candidate 节点收到来自主节点的信息后,会立即终止选举过程,进入 Follower 角色;
- 为了避免陷入选主失败的循环,每个节点因为没有收到 heartbeat 而发起选举的时间是一定范围内的随机值,这样可以避免 2 个节点同时发起选主。
日志复制
日志复制指的是:主节点将每次操作形成日志条目,并持久化到本地磁盘,然后通过网络 I/O 发送给其它节点。当前 Leader 收到 Client 的事务请求后,先把该日志追加到本地 Log 中,然后通过 heartbeat 把日志同步给其它 Follower,Follower 接收到日志后记录日志然后向 Leader 发送 ACK,当 Leader 收到超过半数 Follower 的 ACK 信息后将该日志设置为已提交并追加到本地磁盘中,将结果返回给 Client,在下一个 heartbeat 中 Leader 将通知所有的 Follower 将该日志持久化到本地。
安全性
选举以及日志复制并不能保证节点间数据完全一致。有一种可能性为:如果某个节点挂掉并在一定时间以后恢复重启,由于挂掉的时候会缺失部分日志,若这个节点当选为 Leader,那么不完整的日志记录会覆盖掉其它节点上完整的日志数据。所以 Raft 协议在选主逻辑中,对能够成为 Leader 的节点加以限制,确保选出的主节点一定包含集群已经提交的所有日志数据。
节点数量为奇数
根据 Raft 协议,节点越多,会降低集群的写性能。在同等配置条件下,节点越少,集群性能越高。并且通常按照需求将部署节点数量定为 3、5、7 ... 等奇数个节点。主要原因是偶数个节点集群不可靠风险更高,在选主的过程中,存在较大概率获得等额选票,导致触发下一轮的选举。
6.3 Etcd 在 Kubernetes 中的应用
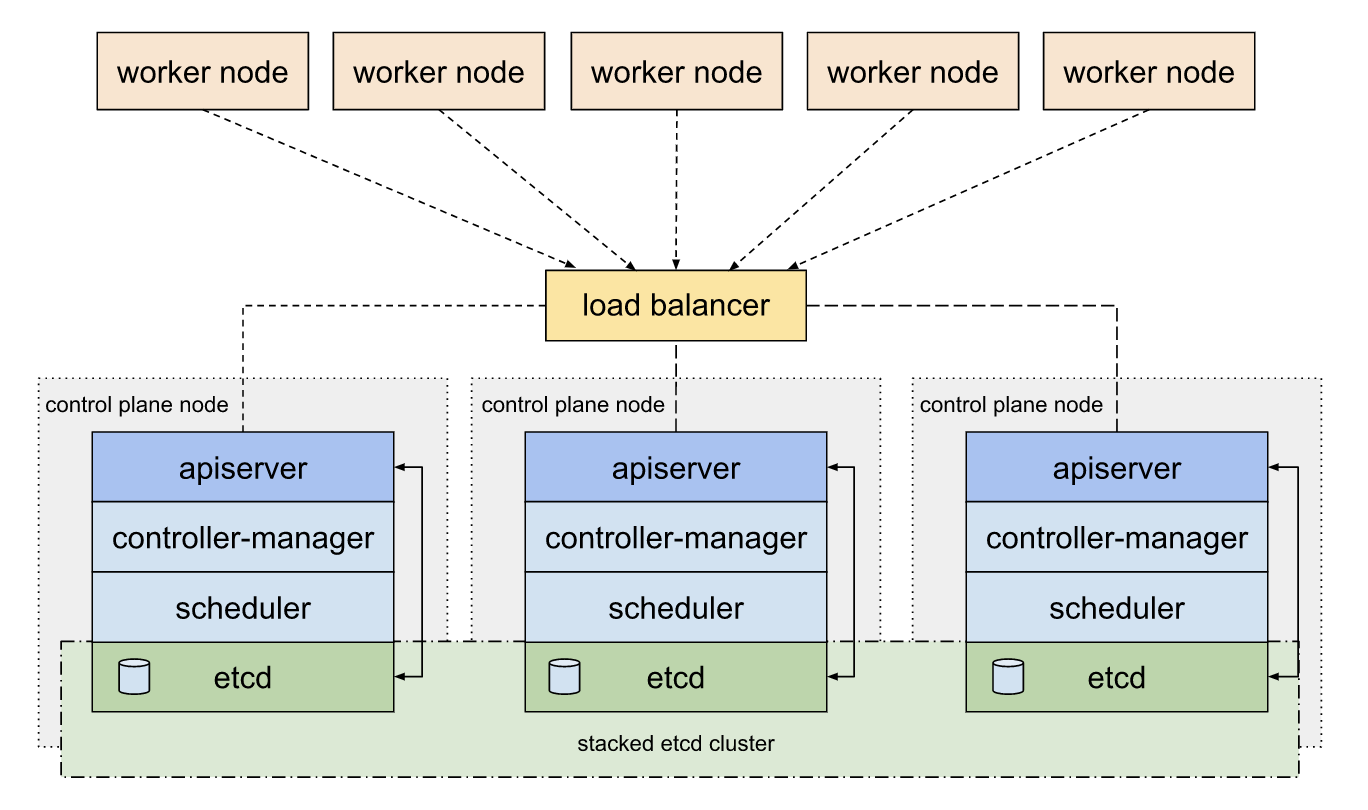
在 Kubernetes 集群中,Etcd 被用作服务发现和集群状态、配置存储的后端,Etcd 实例被部署运行在 Master 节点的 Pod 中。
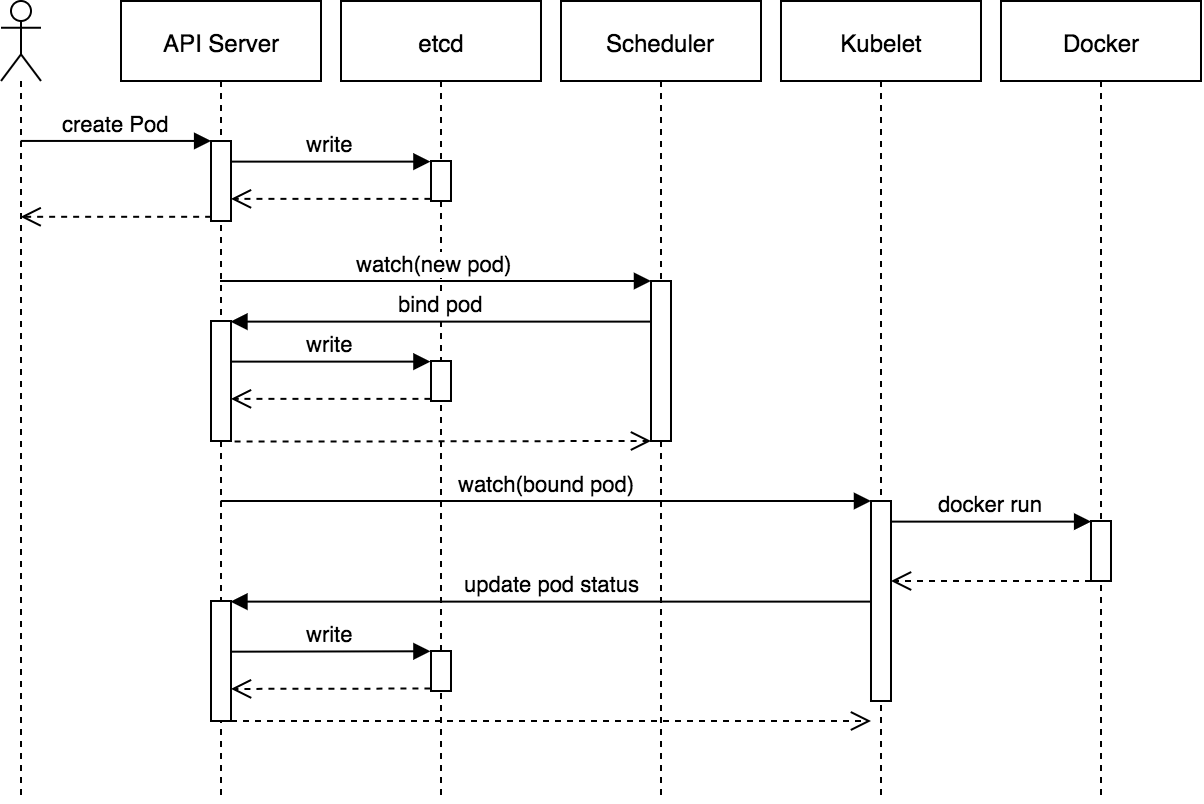
下面的图片展示了一个 Pod 完整的创建过程,可以清楚的看到 API Server 与 Etcd 之间的交互:
首先我们查看 etcd Pod 的名称,可以看到这个 Pod 属于 kube-system 命名空间:
$ kubectl get pods --all-namespaces | grep etcd
kube-system etcd-kubesphere01 1/1 Running 0 65d
在终端执行如下命令获取 etcd-kubesphere01 Pod 中关于 etcd 容器运行的配置信息:
$ kubectl exec -it -n kube-system etcd-kubesphere01 sh
# ss -lnp|grep etcd
u_dgr UNCONN 0 0 @00030 36645 * 0 users:(("etcd",pid=1,fd=3))
tcp LISTEN 0 128 192.168.0.31:2379 *:* users:(("etcd",pid=1,fd=7))
tcp LISTEN 0 128 127.0.0.1:2379 *:* users:(("etcd",pid=1,fd=6))
tcp LISTEN 0 128 192.168.0.31:2380 *:* users:(("etcd",pid=1,fd=5))
tcp LISTEN 0 128 127.0.0.1:2381 *:* users:(("etcd",pid=1,fd=11))
评论区