


4.1 kubelet 运行机制
kubelet 功能及模块
kubelet 的主要功能包括:
- pod 管理:kubelet 定期从 Api Server 接口获取 Node 上的 pod 或是 container 的期望状态(比如使用什么镜像创建容器、运行的 pod 副本数量、如何配置网络以及存储),并调用容器平台接口达到这个状态。
- 容器健康检查:kubelet 创建容器后需要检查容器是否正常运行,如果没有正常运行会根据 pod 重启策略进行处理。
- 容器监控:通过 cAdvisor 监控所在 Node 的资源使用情况并定时向 Master 汇报,便于 Master 了解 Node 的整体情况。
下图展示了 kubelet 组件中的模块:
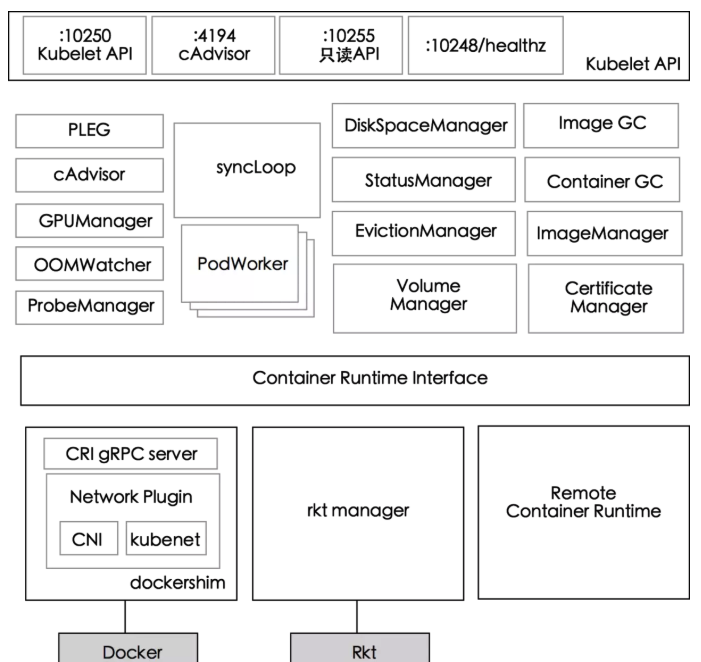
各模块的功能分别为:
PLEG(Pod Lifecycle Event Generator): kubelet 的核心模块,PLEG 会一直调用 container runtime 获取本节点 containers/sandboxes 的信息,并与自身维护的 pods cache 信息进行对比,生成对应的 PodLifecycleEvent,然后输出到 eventChannel 中,通过 eventChannel 发送到 kubelet syncLoop 进行消费,然后由 kubelet syncPod 来触发 pod 同步处理过程,最终达到用户的期望状态。cAdvisor: Google 开源的容器监控工具,默认集成在 kubelet 中,用于收集 node 和 container 的监控信息,这个模块对外提供调用接口,可以被 ImageManager、OOMWatcher、ContainerManager 等使用。OOMWatcher: 系统 OOM 的监听器,会与 cAdvisor 模块之间建立 SystemOOM,通过 Watch 的方式从 cAdvisor 获取 OOM 信号,并产生相关事件。ProbeManager: 定时监控 pod 中容器的健康状况,支持两种类型的探针:livenessProbe、readinessProbe。StatusManager: 维护状态信息,把 pod 状态更新到 API Server。EvictionManager: 当节点的资源不足情况以及达到配置的 evict 策略时,node 会变为 pressure 状态,kubelet 会按照 qosClass 的顺序驱逐 pod 以保证节点的稳定性。VolumeManager: 负责 node 上 pod 使用的存储卷管理。ImageGC: 负责 node 节点的镜像回收。存储在本地的镜像的磁盘使用空间达到设定的某一阈值时会触发镜像回收,删除掉没有被 pod 使用的镜像。ContainerGC: 清理掉节点上没有停止的 container。ImageManager: 负责 pod 上的镜像管理。
4.2 kubelet 启动参数
下面的清单展示了 kubelet 的启动参数:
--allowed-unsafe-sysctls: 设置允许的非安全 sysctls 或 sysctl 模式白名单,由于操作的是操作系统,所以需要小心控制--bootstrap-checkpoint-path: 保存 checkpoint 的目录--bootstrap-kubeconfig: 获取 kubeconfig 配置文件路径--cert-dir: TLS 证书所在目录,默认值为 /var/run/kubernetes--cni-bin-dir: CNI 插件二进制文件所在目录,默认值为 /opt/cni/bin--cni-conf-dir: CNI 插件配置文件所在目录,默认值为 /etc/cni/net.d--config: kubelet 主配置文件--container-runtime: 容器类型,默认值为 docker--enable-server: 启动 kubelet 上的 HTTP Rest Server,该服务提供了获取在本节点上运行的 Pod 列表、pod 状态和其他管理监控相关的 Rest 接口,默认值为 true--exit-on-lock-contention: 设置为 true 表示当有文件锁存在时 kubelet 也可以退出--hostname-override: 设置 Node 在集群中的主机名,不设置将使用本机的 hostname--housekeeping-interval: 对容器进行 housekeeping 操作的时间间隔,默认值为 10s--image-pull-progress-deadline: 如果已经到达设置的时间但还没有开始 pull 镜像,那么拉取镜像的操作会被取消,默认值为 1m0s--kubeconfig: kubeconfig 配置文件路径,配置文件中包含 Master 地址信息以及必要的认证信息,默认值为 /var/lib/kubelet/kubeconfig--pod-infra-container-image: 用于 Pod 内网络命名空间共享的基础 pause 镜像,默认值为 k8s.gcr.io/pause:3.1--provider-id: 设置主机数据库中标识 Node 的唯一 ID--redirect-container-streaming: 启用容器流数据并重定向给 API Server。设置为 false 表示 kubelet 将代理 API Server 和容器运行时之间的容器流数据。设置为 true 表示 kubelet 将容器运行时重定向给 API Server,之后 API Server 可以直接访问容器运行时。代理模式更安全,但是会浪费一些性能;重定向模式性能更好,但是安全性更低,因为 API Server 和容器运行时之间的连接可能无法进行身份认证--register-node: 将本 Node 注册到 API Server,默认值为 true--root-dir: kubelet 运行根目录,将保持 Pod 和 Volume 的相关文件,默认值为 /var/lib/kubelet--runonce: 设置为 true 表示创建完 Pod 之后立即退出 kubelet 进程--runtime-cgroups: 为容器 runtime 设置的 cgroup--volume-plugin-dir: 搜索第三方 Volume 插件的目录,默认值为 /usr/libexec/kubernetes/kubelet-plugins/volume/exec/
4.3 Node 管理
对于 Node 的管理,我们经常关注的是启动参数 --register-node:
当这个值为 true 时,kubelet 会通过 API Server 注册所在的 Node 节点。如果遇到集群资源不足的情况,我们可以通过添加机器和运用 kubelet 的自注册模式实现扩容。在注册的时候通常还会使用到的参数有:
--api-servers用于设置 API Server 的位置;--kubeconfig用于访问 API Server 的安全配置文件;--cloud-provider用于设置云服务商 (IaaS) 地址,仅适用于公有云环境。
当这个值为 false 时,表示没有使用 kubelet 自注册模式,我们需要手动创建节点信息,自己配置 Node 的资源信息,并告知 Node 上 Kubelet API Server 的位置。
kubelet 还有一个较常见的启动参数为 --node-status-update-frequency,用于设置 kubelet 每隔过长时间向 API Server 报告节点状态,默认值为 10s。API Server 在接收到这些信息以后,会将这些信息写入 etcd 中。
4.4 Pod 管理
kubelet 通过以下的 3 种方式获取自身 Node 上要运行的 Pod 清单:
- 文件:kubelet 通过启动参数
--config指定配置文件目录,默认目录地址为/etc/kubernetes/manifests/。使用参数--file-check-frequency设置检查该文件目录的时间间隔,默认值为 20s。 - HTTP 端点 (URL):使用参数
--manifest-url设置,通过参数--http-check-frequency设置检查该 HTTP 端点的时间间隔,默认值为 20s。 - API Server:通过 API Server 监听 etcd 目录,同步 Pod 列表。
以文件和 HTTP 端点的方式创建的 Pod 被称为 Static Pod。kubelet 会将 Static Pod 的状态汇报给 API Server,API Server 会创建一个 Mirror Pod 与 Static Pod 进行匹配,它们之间的状态也会进行同步,当删除 Static Pod 时,对应的 Mirror Pod 也会被删除。
Static Pod 大家作为了解即可,这里我们还是主要介绍通过 API Server 获取 Pod 清单的方式。
kubelet 通过 API Server Client 使用 Watch 加 List 的方式监听 /registry/nodes/$ 当前节点的名称和 /registry/pods 目录,将获取到的信息同步到本地缓存中。
kubelet 会监听 etcd,所有针对 Pod 的操作都会被 kubelet 监听,常用的操作可以分为以下 3 类:
- 在本节点创建新的 Pod:按照 Pod 清单要求创建 Pod;
- 修改本节点的 Pod:按照要求修改 Pod,比如要求删除 Pod 中的某个容器,就通过 Docker Client 删除 Pod 中的容器;
- 删除本节点的 Pod:按照要求删除 Pod,kubelet 会按照要求删除 Pod,并通过 Docker Client 删除 Pod 中的容器。
对于在本节点创建和修改 Pod,具体的执行步骤如下所示:
- 为该 Pod 创建一个数据目录;
- 从 API Server 读取该 Pod 清单;
- 为该 Pod 挂载外部卷 (External Volume);
- 下载 Pod 用到的 Secret;
- 检查已经运行在节点上的 Pod,如果该 Pod 没有容器或 Pause 容器没有启动(由 “kubernetes/pause” 镜像创建的容器),则先停止 Pod 里所有容器的进程。如果在 Pod 中有需要删除的容器,则删除这些容器;
- 用 “kubernetes/pause” 镜像为每个 Pod 都创建一个容器,创建的 Pause 容器用于接管 Pod 中所有其他容器的网络。每次创建新的 Pod,kubelet 都会先创建一个 Pause 容器,然后再创建其他的容器。“kubernetes/pause” 镜像非常小,只有 200 KB 左右的大小;
- 为 Pod 中的每个容器执行如下处理:
- 为容器计算一个 Hash 值,然后用容器的名称去查询对应 Docker 容器的 Hash 值,如果查找到容器并且两者的 Hash 值不同,就停止 Docker 容器中的进程,并停止和它相关联的 Pause 容器的进程;如果两者的 Hash 值相同就不做任何处理;
- 如果容器被终止,并且容器没有指定的 restartPolicy(重启策略),就不做任何处理;
- 调用 Docker Client 下载容器镜像并运行容器。
4.5 容器健康检查
Pod 通过两类探针来检查容器的健康状态:
ReadinessProbe探针:判断容器是否启动成功,并准备接收请求。如果检测到容器启动失败,则 Pod 的状态将被修改,Endpoint Controller 将从 Service 的 Endpoint 中删除包含该容器所在 Pod 的 IP 地址的 Endpoint 条目。LivenessProbe探针:判断容器是否健康并反馈给 kubelet。如果检测到容器不健康,kubelet 将删除该容器,并根据容器的重启策略做相应的处理,如果一个容器不包含 LivenessProbe 探针,那么 kubelet 认为该容器的 LivenessProbe 探针返回的值永远是 Success。
kubelet 定期调用容器中的 LivenessProbe 探针来诊断容器的健康状况,主要包含以下 3 种实现方式:
ExecAction:在容器内部执行一个命令,如果该命令的退出状态码为 0,表示容器健康;TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检查,如果端口能够访问就表明容器健康;HTTPGetAction:通过容器的 IP 地址和端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,就可以认为容器状态健康。
LivenessProbe 探针被包含在 Pod 定义的 spec.containers.{某个容器} 中,下面有两个例子可以作为参考。
使用 ExecAction 方式执行健康检查,kubelet 在容器中执行 cat /tmp/health 命令,如果返回值为 0,就表示容器处于健康状态:
livenessProbe:
exec:
command:
- cat
- /tmp/health
initialDelaySeconds: 15
timeoutSeconds: 1
使用 HTTPGetAction 方式执行健康检查,kubelet 会发送一个 HTTP 请求到本地主机、端口及制定路径,来检查容器的健康状态:
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
timeoutSeconds: 1
4.6 资源监控
在 Kubernetes 集群中,应用程序的执行情况可以在不同的级别上检测到,这些级别包括:容器、Pod、Service 和整个集群。用户通过分析不同级别的资源使用信息,从而深入地了解应用的执行情况,并找到应用中可能的瓶颈进行优化。
在 Kubernetes 1.13 版本之前可以使用 cAdvisor 以及 Heapster 实现集群范围内全部容器性能指标的采集和查询功能。cAdvisor 是谷歌开源的分析容器资源使用率和性能特性的代理工具,它可以自动查找所在 Node 上的容器,自动采集 CPU、内存、文件系统和网络使用的统计信息,cAdvisor 通过所在节点的 4194 端口暴露一个简单的 UI,只是 cAdvisor 只能提供 2~3min 的监控数据,也不提供数据持久化,所以还需要配合 Heapster 一起使用。
在 Kubernetes 1.13 版本之后 Heapster 已经彻底废弃,转而使用 Metrics Server 组件来监控 Kubernetes 集群资源使用情况。Metrics Server 提供 Core Metrics(核心指标),包括 Node 和 Pod 的 CPU 和内存使用数据,其它 Custom Metrics(自定义指标)由第三方组件(比如 Prometheus)采集和存储。
metrics-server 提供了 Metrics API 来获取集群中的资源使用情况度量,需要注意以下 3 点:
- Metrics API 只能够查询当前的度量数据,不能够保存历史数据
- Metrics API URI 为 /apis/metrics.k8s.io/
- 必须部署 metrics-server 才能使用 Metrics API,metrics-server 通过调用 Kubelet Summary API 获取数据
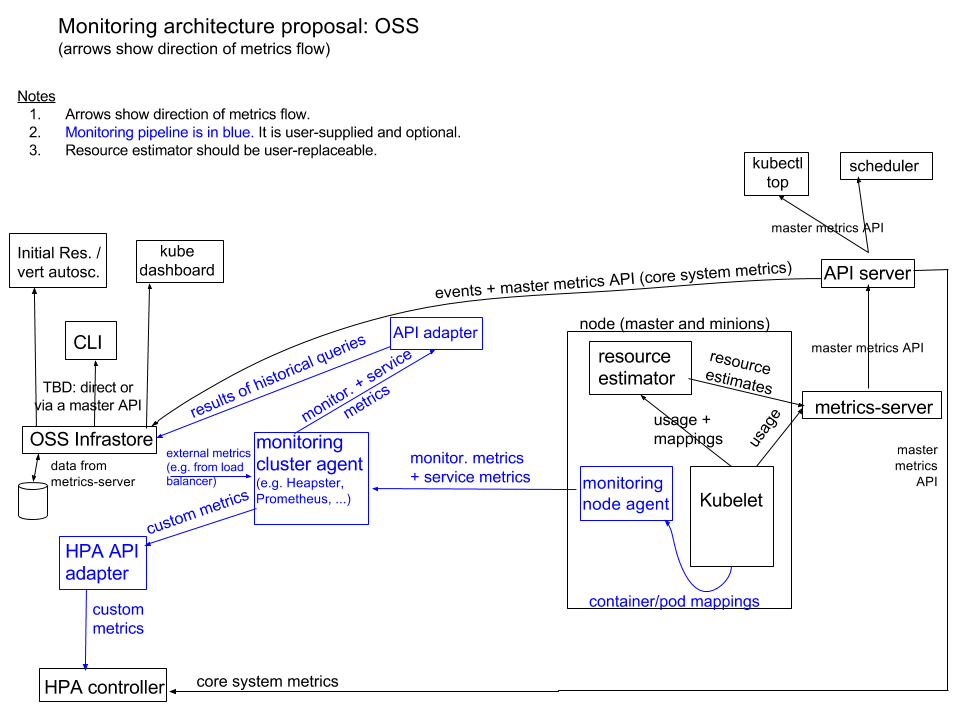
Kubernetes 监控架构 由两部分组成:
- 核心度量流程(下图黑色部分):Kubernetes 正常工作所需要的核心度量,从 Kubelet、cAdvisor 等获取度量数据,再由 metrics-server 提供给 Dashboard、HPA 控制器等使用。
- 监控流程(下图蓝色部分):基于核心度量构建的监控流程,比如 Prometheus 从 metrics-server 获取核心度量,再从其它数据源(如 Node Exporter 等)获取非核心度量,再基于他们构建监控告警系统。
查看 metrics-server pod 和 service 是否运行起来:
$ kubectl get pods -o wide|grep metrics-server
metrics-server-66444bf745-7vwd5 1/1 Running 0 64d 10.20.177.67 kubesphere03 <none> <none>
$ kubectl get svc -A|grep metrics-server
kube-system metrics-server ClusterIP 10.96.192.25 <none> 443/TCP 64d
也可以查看 apiservices 是否开启:
$ kubectl get apiservices|grep metrics-server
v1beta1.metrics.k8s.io kube-system/metrics-server True 64d
通过 kubectl 命令访问这些 Metrics API,比如:
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
kubectl get --raw /apis/metrics.k8s.io/v1beta1/pods
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes/<node-name>
kubectl get --raw /apis/metrics.k8s.io/v1beta1/namespace/<namespace-name>/pods/<pod-name>
评论区