


7.1 手动扩缩容
通过命令 kubectl scale 可以进行手动扩缩容,使用参数 --replicas 指定需要增加或是减少 Pod 的数量到某个指定的数字。
通过一个实例来体会手动扩缩容的效果,新建 nginx-deployment.yaml 文件,并向其中写入如下内容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
执行创建:
$ kubectl create -f nginx-deployment.yaml
deployment.apps/nginx-deployment created
现在预期会有 3 个 nginx-deployment Pod 副本运行中:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-687548bb8c-7skkg 1/1 Running 0 38s
nginx-deployment-687548bb8c-h27kj 1/1 Running 0 38s
nginx-deployment-687548bb8c-xcbnq 1/1 Running 0 38s
首先,进行扩容,将 nginx-deployment Pod 副本数量从 3 个扩容到 5 个:
$ kubectl scale deployment nginx-deployment --replicas=5
deployment.apps/nginx-deployment scaled
可以看到有两个新创建的pod:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-687548bb8c-7skkg 1/1 Running 0 2m29s
nginx-deployment-687548bb8c-h27kj 1/1 Running 0 2m29s
nginx-deployment-687548bb8c-hq4n4 1/1 Running 0 19s
nginx-deployment-687548bb8c-s4rlc 1/1 Running 0 19s
nginx-deployment-687548bb8c-xcbnq 1/1 Running 0 2m29s
然后,进行缩容,将 nginx-deployment Pod 副本数量从 5 个缩容到 1 个:
$ kubectl scale deployment nginx-deployment --replicas=1
deployment.apps/nginx-deployment scaled
可以看出,系统 kill 掉了一些运行中的 Pod,只保留了一个 Pod 来实现缩容:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-687548bb8c-7skkg 1/1 Running 0 4m10s
7.2 自动扩缩容
从 Kubernetes v1.1 版本开始,添加了名为 Horizontal Pod Autoscaler(HPA) 的控制器,用于实现 Pod 自动扩缩容的功能。HPA 控制器基于 Master 的 kube-controller-manager 服务启动参数 --horizontal-pod-autoscaler-sync-period 定义的检测周期(默认值为 15s),周期性检测目标 Pod 的资源性能指标,并与 HPA 资源对象中的扩缩容条件进行对比,当满足条件时对 Pod 副本数量进行调整。
通常而言,扩缩容会根据内存、CPU 资源使用率、或是自定义的业务监控指标作为资源性能指标,前面介绍过现在 Kubernetes 系统的资源采集指标主要由两种 API 进行实现(而传统的 Heapster 监控已经被废弃):
- Resource Metrics API(通过 metrics-server 实现):负责采集 Node、Pod 的核心资源数据
- Custom Metrics API(通常使用 Prometheus 实现):负责自定义的指标数据采集,比如:网卡流量、磁盘 IOPS、HTTP 请求数、数据库连接数等
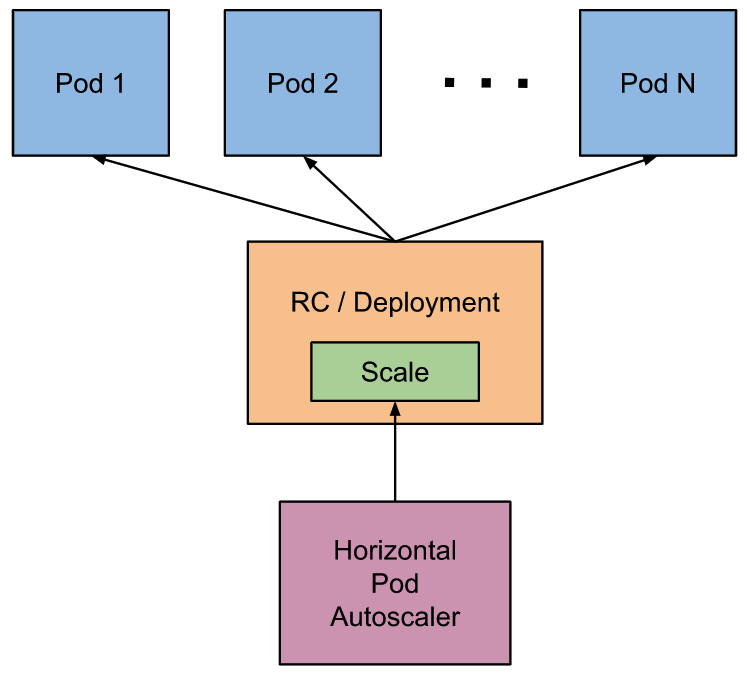
扩缩容算法
Autoscaler 控制器从聚合 API 获取到 Pod 性能指标数据之后,通过下面的算法计算目标 Pod 副本数量:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
目标副本数量 = 当前副本数 * (当前指标值/期望指标值)
注意上面公式的计算结果需要向上取整,然后将目标副本数量与当前副本数量进行对比,就可以判断是否需要进行扩容或是缩容。
以 CPU 请求数量为例,假设当前系统运行了一个 Pod 副本,用户设置的期望值为 100m:
- 如果当前实际使用的指标值为 200m,则:目标副本数量 = 1 * (200/100) = 2,也就是期望 Pod 副本数量为 2,这个时候就会进行 Pod 扩容
- 如果当前实际使用的指标值为 50m,则:目标副本数量 = 1 * (50/100) = 0.5,将计算结果向上取整为 1,也就是期望 Pod 副本数量为 1,这个时候就不会改变 Pod 的数量
当计算结果与 1 非常接近时,可以设置一个容忍度使系统不做扩缩容处理,通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-tolerance 进行设置,该参数的默认值为 0.1(10%),所以上述算法计算结果在正负 10% 的区间中都不会执行扩缩容操作。
期望指标值(desiredMetricValue)也可以是指标的平均值,比如:targetAverageValue,这时当前指标值(currentMetricValue)的算法为:
当前指标值 = 所有 Pod 副本当前指标值总和 / Pod 副本数量
php-apache 自动扩缩容实例
先来运行一个自动扩缩容的例子进行实际的体验。
首先在系统中应部署好资源监控 metrics-server,当能够成功获取 Pod 的 CPU 和 MEMORY 信息时说明 metrics-server 已经部署好:
$ kubectl top pods -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-589b5f594b-g86zn 2m 18Mi
calico-node-5rpwf 17m 45Mi
calico-node-66cl4 20m 44Mi
calico-node-xqf6p 23m 42Mi
coredns-67c766df46-4vg25 3m 17Mi
coredns-67c766df46-wkwf5 4m 14Mi
etcd-kubesphere01 11m 284Mi
kube-apiserver-kubesphere01 34m 634Mi
kube-controller-manager-kubesphere01 11m 87Mi
kube-proxy-7gxj2 3m 22Mi
kube-proxy-frjw4 5m 21Mi
kube-proxy-tx6n7 1m 19Mi
kube-scheduler-kubesphere01 2m 29Mi
metrics-server-66444bf745-7vwd5 1m 23Mi
nfs-client-provisioner-7f959768b5-vchmj 2m 10Mi
tiller-deploy-6d8dfbb696-r968q 1m 17Mi
本次实验中将会运行一个自定义的 hpa-example 镜像,本镜像由基础镜像 php-apache 修改制作而成,Dockerfile 的内容如下所示:
FROM webdevops/php-apache:latest
ADD index.php /app/index.php
RUN chmod a+rx /app/index.php
其中使用到的 index.php 页面的内容如下:
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
使用 hpa-example 镜像运行一个 Deployment,并使用 80 端口对外提供服务:
$ kubectl run php-apache --image=hpa-example:1.0 --requests=cpu=200m --limits=cpu=500m --expose --port=80
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
service/php-apache created
deployment.apps/php-apache created
查看是否创建好:
# 获取到 php-apache 服务的虚拟集群 IP 地址:10.96.115.130,后面将会使用到
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
php-apache ClusterIP 10.96.115.130 <none> 80/TCP 19s
# 可以发现这个时候只运行了一个 Pod
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 28s
当服务创建好以后,使用 kubectl autoscale 命令创建 Pod 水平自动伸缩,下面的命令指定了 php-apache Deployment 的 Pod 副本数量范围:最少为 1 个,最多为 10 个;同时我们指定平均 CPU 利用率为 50%,简单的说 HPA 会通过增加或是减少 Pod 的副本数量,来维持所有 Pod 的平均 CPU 利用率为 50%(前面在创建 Deployment 时指定最少的 CPU 为 200m,所以平均 CPU 的利用率为 100m)。
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
horizontalpodautoscaler.autoscaling/php-apache autoscaled
查看刚刚创建的 HPA:
# 由于目前没有向服务器发送请求,所以当前 CPU 的消耗为 0%,这里的数值为所有 Pod 的 CPU 消耗平均值
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 25s
接下来将会增加服务的工作负荷,以此来观察 Pod 水平自动伸缩的效果。使用 busybox 镜像创建并启动一个名为 load-generator 的 Pod,并执行命令无限循环的向 php-apache 服务发送查询请求,新开一个终端执行如下命令:(可以看到每一次查询成功都会有一个 OK!输出)
$ kubectl run -it load-generator --image=busybox /bin/sh
/ # while true;do wget -q -O- http://10.96.115.130/index.php;done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK...
大概等半分钟左右,查看 php-apache HPA 的信息可以发现由于持续不断的查询请求导致 CPU 负载变高,现在已经超过定义的平均值 50% 激增到 250% 了:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 250%/50% 1 10 1 7m38s
...
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 84%/50% 1 10 4 20m
...
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 52%/50% 1 10 9 25m
由于 CPU 平均消耗超过了预设值,这个时候就会触发 Kubernetes 系统 Pod 的水平自动扩容,但是扩容范围也必须少于设定的最大值 10:
$ kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 9/9 9 9 28m
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
load-generator-5fb4fb465b-92884 1/1 Running 0 24m
php-apache-78d7965bbb-4qkdc 1/1 Running 0 5m7s
php-apache-78d7965bbb-6bp4q 1/1 Running 0 5m7s
php-apache-78d7965bbb-7zghg 1/1 Running 0 3m4s
php-apache-78d7965bbb-7zzp2 1/1 Running 0 7m49s
php-apache-78d7965bbb-cc9pc 1/1 Running 0 3m4s
php-apache-78d7965bbb-ffqqv 1/1 Running 0 4m51s
php-apache-78d7965bbb-ffxhk 1/1 Running 0 4m6s
php-apache-78d7965bbb-lz4d6 1/1 Running 0 4m6s
php-apache-78d7965bbb-p2dm2 1/1 Running 0 5m7s
现在停止服务请求的发送,在运行 busybox 镜像的终端按 Ctrl+C 停止。当请求停止,CPU 工作负载降低,这个时候就会触发 Kubernetes 系统 Pod 的水平自动缩容,缩容范围也不能小于设定的最小值 1:(这个自动缩容的过程可能需要持续好几分钟的时间才能完成,请耐心等待一下才能够查看到效果。)
# 由于停止了请求,最终 HPA 显示的 CPU 平均负载会固定到 0%
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 31m
# HPA 完成了自动缩容,现在 php-apache Deployment 只有一个 Pod 在运行中了,其余的 Pod 都被系统 kill 掉了
$ kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 35m
# 查看最终剩下的一个 Pod 的名称
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
load-generator-5fb4fb465b-92884 1/1 Running 0 31m
php-apache-78d7965bbb-7zzp2 1/1 Running 0 15m
# 查看整个 php-apache Deployment 的 Events,可以发现 Pod 的数量变化过程
$ kubectl describe deployments.apps php-apache
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 36m deployment-controller Scaled up replica set php-apache-5c744c6969 to 1
Normal ScalingReplicaSet 26m deployment-controller Scaled up replica set php-apache-5c744c6969 to 4
Normal ScalingReplicaSet 26m deployment-controller Scaled up replica set php-apache-5c744c6969 to 5
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set php-apache-5c744c6969 to 1
Normal ScalingReplicaSet 16m deployment-controller Scaled up replica set php-apache-78d7965bbb to 1
Normal ScalingReplicaSet 16m deployment-controller Scaled down replica set php-apache-5c744c6969 to 0
Normal ScalingReplicaSet 13m deployment-controller Scaled up replica set php-apache-78d7965bbb to 4
Normal ScalingReplicaSet 13m deployment-controller Scaled up replica set php-apache-78d7965bbb to 5
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set php-apache-78d7965bbb to 7
Normal ScalingReplicaSet 3m (x2 over 11m) deployment-controller (combined from similar events): Scaled down replica set php-apache-78d7965bbb to 1
查看当前 php-apache HPA 的详细信息:
$ kubectl describe hpa php-apache
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 17m (x2 over 17m) horizontal-pod-autoscaler unable to get metrics for resource cpu: no metrics returned from resource metrics API
Warning FailedComputeMetricsReplicas 17m (x2 over 17m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics API
Warning FailedComputeMetricsReplicas 16m (x4 over 17m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready pods
Warning FailedGetResourceMetric 16m (x4 over 17m) horizontal-pod-autoscaler did not receive metrics for any ready pods
Normal SuccessfulRescale 15m (x2 over 28m) horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 14m (x2 over 27m) horizontal-pod-autoscaler New size: 5; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 14m horizontal-pod-autoscaler New size: 7; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 12m horizontal-pod-autoscaler New size: 9; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 4m16s (x2 over 22m) horizontal-pod-autoscaler New size: 1; reason: All metrics below target
上面的整个过程就向我们完整的展示了 HPA 自动扩缩容的过程。
7.3 配置 HPA
在前面我们使用的是命令行的方式直接定义扩缩容规则,这一般用于简单规则的情况。对于需要定义复杂或是多样的扩缩容规则,则可以使用 HorizontalPodAutoscaler 资源对象来实现自定义。
HorizontalPodAutoscaler 资源对象属于 autoscaling API 组,它包括两个版本:
- v1版本:只支持基于 CPU 使用率的自动扩缩容配置
- v2版本:支持基于任意指标的自动扩缩容配置,比如:资源使用率、Pod 指标、其它指标等,目前广泛使用的版本为 autoscaling/v2beta2
v1 版本
在前面的示例中,通过 CPU 的平均使用率配置扩缩容,在上面使用的是命令的方式直接配置,其实也可以手动使用 YAML 文件创建自动伸缩,可以直接使用 autoscaling/v1 版本,新建 php-apache-hpa.yaml 文件,并写入如下内容:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
# 目标作用对象 scaleTargetRef
scaleTargetRef:
apiVersion: apps/v1
# 类型 kind,可以为 Deployment、rc 或是 rs
kind: Deployment
name: php-apache
# Pod 副本数量的最小值
minReplicas: 1
# Pod 副本数量的最大值
maxReplicas: 10
# 期望每个 Pod 的 CPU 使用率 targetCPUUtilizationPercentage,这里设置为 50%,这个使用率基于 Pod 设置的 CPU Request 值进行计算,在前面设置了 requests cpu 为 200m,所以系统会维持 Pod 的实际 CPU 使用率为 100m
targetCPUUtilizationPercentage: 50
v2beta2 版本
如果使用 autoscaling/v2beta2 API 版本进行设置,则前面定义的 YAML 文件内容应该改写为如下所示:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
# 在 v2beta2 版本中,使用 metrics 字段定义目标指标值
metrics:
# type 字段表示指标类型
- type: Resource
resource:
name: cpu
# target 字段定义指标的目标值,系统在指标数据达到目标值时将触发扩缩容操作
target:
type: Utilization
averageUtilization: 50
metrics.type 指标类型可以设置为如下三种中的任一一个或是多个的组合:
- Resource: 基于资源的指标值,这里的资源指的是 CPU 和内存 Memory
- Pods: 基于 Pod 的指标值,会将系统中全部 Pod 的指标值进行平均值计算
- Object: 基于某种资源对象(比如 Ingress)的指标值,或是自定义的指标值
对于 Resource 类型指标而言:
- CPU 使用率:在 target.averageUtilization 字段中设置目标平均 CPU 使用率
- 内存 Memory 资源:在 target.AverageValue 字段中设置目标平均内存使用值
- 指标数据通过 metrics.k8s.io API 进行查询
- 必须先启动 Metrics Server 服务
Pods 和 Object 类型指标都属于自定义指标类型,它们的共同点在于:
- 指标数据通过搭建自定义 Metrics Server 服务和监控工具获取
- 指标数据通过 custom.metrics.k8s.io API 进行查询
- 必须先启动自定义的 Metrics Server 服务
Pods 类型指标的数据是从系统中所有 Pod 获取到的,所以 target.type 字段只能使用 AverageValue,比如我们需要设置一个 Pods 类型指标名为 packets-per-second,要求在目标指标平均值为 1000 时触发扩缩容操作,则对应的 YAML 文件定义如下所示:
metrics:
# type 字段表示指标类型
- type: Pods
Pods:
# metrics.name 字段设置指标的名字
metrics:
name: packets-per-second
# target 字段定义指标的目标值,系统在指标数据达到目标值时将触发扩缩容操作
target:
type: AverageValue
averageValue: 1k
Object 类型指标数据来源于其它资源对象或是自定义指标,target.type 字段可以为 Value 或是 AverageValue(这时会根据 Pod 数量计算平均值),这里可以看两个示例:
- 数据来源于其它资源对象:设置一个 Object 类型指标名为 requests-per-second,它的值来源于 Ingress “main-route”,当目标值为 2000 时触发扩缩容操作,对应的 YAML 文件格式内容如下:
metrics:
- type: Object
object:
metrics:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
- 数据来源于自定义指标:设置一个 Object 类型指标名为 http_requests,且必须具有标签 “verb=GET”,当指标平均值达到 500 时触发扩缩容操作,对应的 YAML 文件格式内容如下:
metrics:
- type: Object
object:
metrics:
name: "http_requests"
selector: "verb=GET"
target:
type: AverageValue
averageValue: 500
当一个 HPA 资源对象定义了多种类型的指标时,系统会针对每一种类型的指标都计算 Pod 目标值,最终会以结果中最大的 Pod 值进行扩缩容操作。
从 Kubernetes v1.10 版本开始,metrics.type 指标类型新增了一个名为 External 的值:
- 可以支持外部系统指标,比如公有云服务商提供的消息服务或是外部负载均衡器,
- 指标数据通过 external.metrics.k8s.io API 进行查询
- 必须先启动自定义的 Metrics Server 服务
比如设置一个 External 类型指标名为 queue_messages_ready,且必须具有标签 “queue=worker_tasks”,当指标平均值达到 30 时触发扩缩容操作,对应的 YAML 文件格式内容如下:
metrics:
- type: External
object:
metrics:
name: queue_messages_ready
selector: "queue=worker_tasks"
target:
type: AverageValue
averageValue: 30
不过依然推荐尽量使用 Object 类型的资源对象,因为它和 Kubernetes 系统的集成更加自然紧密。
评论区