


3.1 网络策略原理
网络策略是指基于 Pod 标签实现网络端口的访问控制,对应的资源对象名为 NetworkPolicy。只定义资源对象是不够的,需要具体的策略控制器(Policy Controller)完成策略的实现。Policy Controller 由第三方插件完成,常见的有:Calico、Kube-router、Weave 等开源项目。
网络策略的原理如下所示:
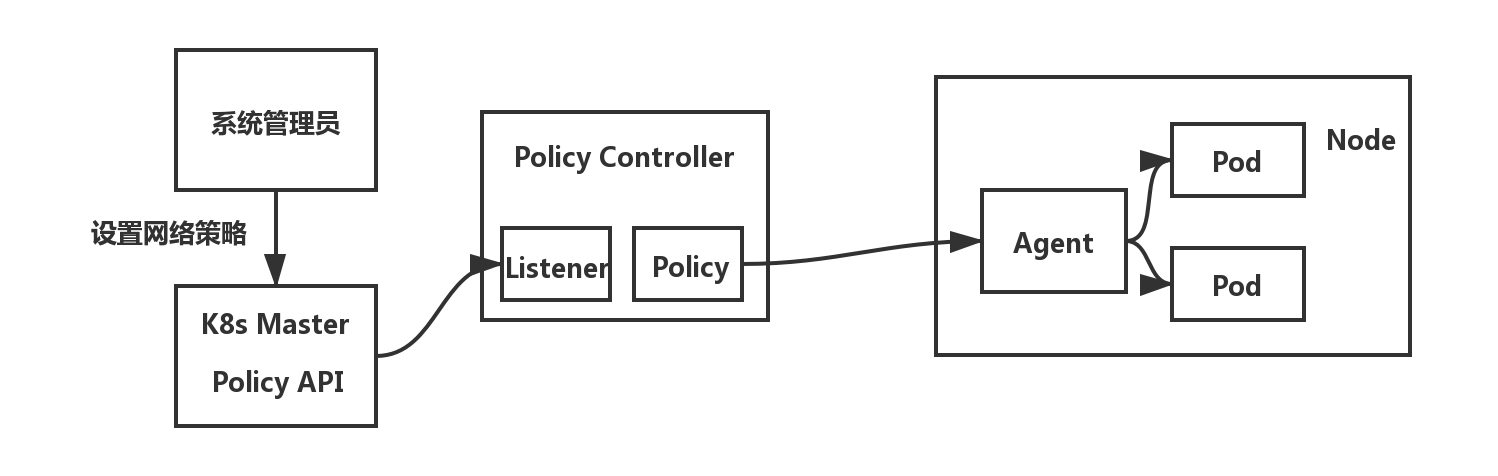
当系统管理员新设置了网络策略,设置结果会存储到 etcd 数据库中。策略控制器(Policy Controller)需要监听设置的策略,然后在 Node 节点上通过客户端 Agent 进行具体的配置(Agent 也是需要通过 CNI 网络插件实现的)。
在 Pod 级别设置网络策略
网络策略主要用于对目标 Pod 的网络访问进行限制。如果不设置网络策略,那么所有 Pod 默认都是可以直接被访问的;当设置了具体的访问策略,只有符合策略要求的网络才被允许访问目标 Pod。
示例如下:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector: # Pod 标签选择器,只有符合条件的 Pod 才会被设置执行网络策略
matchLabels:
role: db # 选择具有 role=db 标签的 Pod
policyTypes: # 网络策略类型
- Ingress # 目标 Pod 入站网络策略
- Egress # 目标 Pod 出站网络策略
ingress: # 访问目录 Pod 的入站白名单
- from: # 满足 from 条件的客户端才能访问下面 ports 定义的目标 Pod 端口号,设置条件可以是:ipBlock、namespaceSelector、podSelector,这三者之间是“或”的关系,只要满足其中任意一个条件就可以访问
- ipBlock: # 客户端的 IP 范围
cidr: 172.17.0.0/16 # 允许的 IP 范围
except: # 不允许的 IP 范围
- 172.17.1.0/24
- namespaceSelector: # 客户端 Pod 所在命名空间需要满足的标签(这里不设置命名空间的话,默认和目标 Pod 处于相同命名空间下)
matchLabels:
project: myproject
- podSelector: # 客户端 Pod 需要满足的标签
matchLabels:
role: frontend
ports: # 允许访问的目标 Pod 监听的端口号
- protocol: TCP
port: 6379
egress: # 目标 Pod 允许访问的“出站”白名单规则,目标 Pod 只允许访问满足以下条件的 IP 地址和端口号
- to: # 允许访问的服务端信息,设置条件可以是:ipBlock、namespaceSelector、podSelector,这三者之间是“或”的关系,只要满足其中任意一个条件就可以访问
- ipBlock:
cidr: 10.0.0.0/24
ports: # 允许访问的服务端端口号
- protocol: TCP
port: 5978
上面的配置总体来说就是设置了如下的限制条件:
- 目标 Pod 是在 “default” 命名空间下具有 “role=db” 标签的所有 Pod。
- 允许从 IP 地址范围 172.17.0.0/16 的客户端 Pod 访问目标 Pod,但是不包括 IP 地址范围 172.17.1.0/24 的客户端。
- 允许属于带有标签 “project=myproject” 命名空间下的客户端 Pod 访问目标 Pod。
- 允许和目标 Pod 处于相同命名空间下的且带有标签 “role=frontend” 的客户端 Pod 访问目标 Pod。
- 只允许使用 TCP 协议访问目标 Pod 的 6379 端口号。
- 允许目标 Pod 访问 IP 地址范围为 10.0.0.0/24,且监听端口为 5978 的服务。
如果想要限制客户端 Pod 和目标 Pod 处于不同命名空间下,且带有特定标签的 Pod,那么设置可以写为:
---
- from: # 表示客户端必须属于带有 project=myproject 标签的命名空间下,且带有 role=frontend 标签的 Pod
- namespaceSelector:
matchLabels:
project: myproject
podSelector:
matchLabels:
role: frontend
在 Namespace 级别设置网络策略
前面提到的是对于目标 Pod 进行网络策略设置,其实还可以对某个命名空间进行全局网络策略的设置。常用的设置有如下几种:
禁止任何客户端访问该命名空间下的所有 Pod
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
允许所有客户端访问该命名空间下的所有 Pod
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress
禁止该命名空间下的所有 Pod 访问外部服务
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Egress
允许该命名空间下的所有 Pod 访问外部服务
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress
禁止所有客户端访问该命名空间下的所有 Pod,且禁止访问外部服务
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
4.1 Calico 简介
Calico 是一个基于 BGP 的纯三层网络方案,可以和 kubernetes、AWS、OpenStack 等云平台良好的集成。Calico 在所有节点通过 Linux Kernel 实现了高效的 vRounter 进行数据转发。每个 vRouter 通过 BGP1 协议把在本节点上运行的容器的路由信息向整个 Calico 网络广播,并自动设置到达其他节点的路由转发规则。
Calico 保证所有容器之间的数据流量都是通过 IP 路由的方式完成互联互通的。Calico 节点组网时可以直接利用数据中心的网络结构(L2/L3),不需要额外的 NAT、隧道或者 Overlay Network,没有额外的封包解包,能够节约 CPU 运算,提高网络效率。
Calico 的 IP 池有两种模式:
- IPIP模式:将各 Node 的路由之间做一个 tunnel,再把两个网络连接起来的模式。启用 IPIP 模式,Calico 会在每个 Node 上创建一个名为 tunl0 的虚拟网络接口。
- BGP模式:直接使用物理机作为虚拟路由器(vRouter),不会额外创建 tunnel。
当 Calico 在小规模集群中部署时可以直接互联,在大规模集群中部署时需要通过额外的 BGP route reflector 进行实现。
Calico 的架构图如下所示:
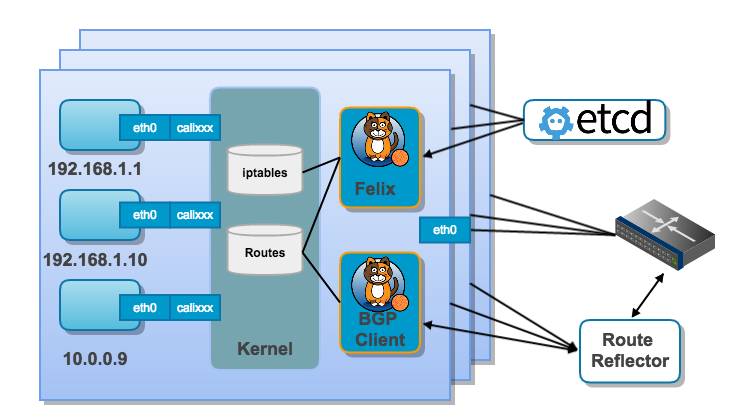
Calico 的主要组件有:
- Felix:Calico Agent,运行在每个 Node 上,负责为容器设置网络资源(包括:IP 地址、路由规则、iptables 规则等),保证跨主机容器网络互通。
- etcd:后端存储网络信息。
- BGP Client:负责把 Felix 在各 Node 上设置的路由信息通过 BGP 协议广播到 Calico 网络。
- Route Reflector:大规模部署时,作为 BGP Client 的中心连接点,完成分级路由分发。
更多关于组件的详细介绍,大家可以参考:Calico architecture。
4.2 集群环境中的 Calico
查看 Pod 的情况:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-589b5f594b-g86zn 1/1 Running 0 81d 10.20.138.1 kubesphere02 <none> <none>
calico-node-5rpwf 1/1 Running 0 81d 192.168.0.33 kubesphere03 <none> <none>
calico-node-66cl4 1/1 Running 0 81d 192.168.0.32 kubesphere02 <none> <none>
calico-node-xqf6p 1/1 Running 0 81d 192.168.0.31 kubesphere01 <none> <none>
可以看到在每个节点都有一个 Calico Agent,在这里体现为有 3 个 calico-node-xxxxx Pod 分别分布在 3 个不同的节点上,同时 calico-kube-controllers-xxx-xxx Pod 在 kube-master 节点上用于设置集群中的网络策略(Network Policy)。
按照 CNI 网络模型的要求,存放 CNI 网络插件配置信息的文件夹路径为 /etc/cni/net.d,存放 CNI 网络插件可执行文件的文件夹路径为 /opt/cni/bin,分别来看这两个目录下存在哪些文件:
$ cd /etc/cni/net.d
# 10-calico.conflist 文件中是 CNI 配置文件内容,calico-kubeconfig 文件中是 Calico 所需的 kubeconfig 配置信息
$ ls
10-calico.conflist calico-kubeconfig
$ cd /opt/cni/bin
# 二进制文件 calico 和 calico-ipam,就是被 kubelet 调用的
$ ls
bandwidth calico dhcp host-device ipvlan macvlan ptp tuning
bridge calico-ipam flannel host-local loopback portmap sample vlan
这里可以关注一下 10-calico.conflist 文件中的内容,定义的是 CNI 网络配置插件:
{
"name": "k8s-pod-network", # 名称
"cniVersion": "0.3.1", # CNI 版本号
# 插件信息,这里定义了两个插件,第一个名为 calico,第二个名为 portmap。多网络插件会按照配置列表中的顺序依次执行,在这里就是会将经过 calico 网络插件处理的结果再传递给 portmap 网络插件继续处理。
"plugins": [
{
"type": "calico", # calico 网络插件
"log_level": "info",
"datastore_type": "kubernetes", # 使用 kubernetes 集群的存储
"nodename": "kubesphere01",
"mtu": 1440,
"ipam": {
"type": "calico-ipam", # 使用 calico-ipam 插件
},
"policy": { "type": "k8s" },
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig", # kubeconfig 文件路径
},
},
{
"type": "portmap", # portmap 网络插件
"snat": true,
"capabilities": { "portMappings": true },
},
],
}
配置了多个网络插件,当删除的时候以逆序的方式执行删除操作,在这里就是先删除 portmap 的配置信息,然后再删除 calico 的配置信息。
接下来看看两个 Node 节点的网络配置。
calico-node 在创建的时候设置了 IP 地址池,node 节点子网的 IP 地址就是从地址池中分配的,可以查看 calico.yaml 文件中的相关定义:
...
- name: CLUSTER_TYPE
value: "k8s,bgp"
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
# Set MTU for tunnel device used if ipip is enabled
- name: FELIX_IPINIPMTU
valueFrom:
configMapKeyRef:
name: calico-config
key: veth_mtu
# The default IPv4 pool to create on startup if none exists. Pod IPs will be
# chosen from this range. Changing this value after installation will have
# no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR
value: "10.20.0.1/16"
...
可以看到这里默认启动了 IPIP 模式,所以节点子网应该存在名为 tunl0 的网络接口。
[root@kubesphere01 ~]# ip addr|grep tunl0@NONE -A3
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.20.143.192/32 brd 10.20.143.192 scope global tunl0
valid_lft forever preferred_lft forever
[root@kubesphere02 ~]# ip addr|grep tunl0@NONE -A3
7: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.20.138.0/32 brd 10.20.138.0 scope global tunl0
valid_lft forever preferred_lft forever
[root@kubesphere03 ~]# ip addr|grep tunl0@NONE -A3
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.20.177.64/32 brd 10.20.177.64 scope global tunl0
valid_lft forever preferred_lft forever
查看路由表:
[root@kubesphere02 ~]# ip route |grep tunl0
10.20.143.192/26 via 192.168.0.31 dev tunl0 proto bird onlink #到kubesphere01节点的私网 10.20.143.192 的路由转发规则
10.20.177.64/26 via 192.168.0.33 dev tunl0 proto bird onlink #到kubesphere03节点的私网 10.20.177.64 的路由转发规则
从上面的结果可以看到,Calico 完成了 Node 间容器网络的设置。当有新的 Pod 调度到这个节点,kubelet 就会通过 CNI 接口调用 Calico 网络插件完成网络的设置,包括 IP 地址、路由规则、iptables 规则等。
5.1 Flannel 简介
与其它的网络插件相比,Flannel 更容易安装和配置。通常它被打包为名为 flanneld 的二进制文件,并且默认集成在 kubernetes 集群部署工具中。Flannel 通过 API 直接使用集群中的 etcd 数据库,所以可以不需要提供专门的数据存储。
Flannel 主要的工作原理为:给每个 Node 上的 Docker 容器分配互相不冲突的 IP 地址,在这些 IP 地址之间建立一个覆盖网络(Overlay Network),通过覆盖网络直接将数据包传递到目标容器中。
Flannel 的工作原理图如下所示:
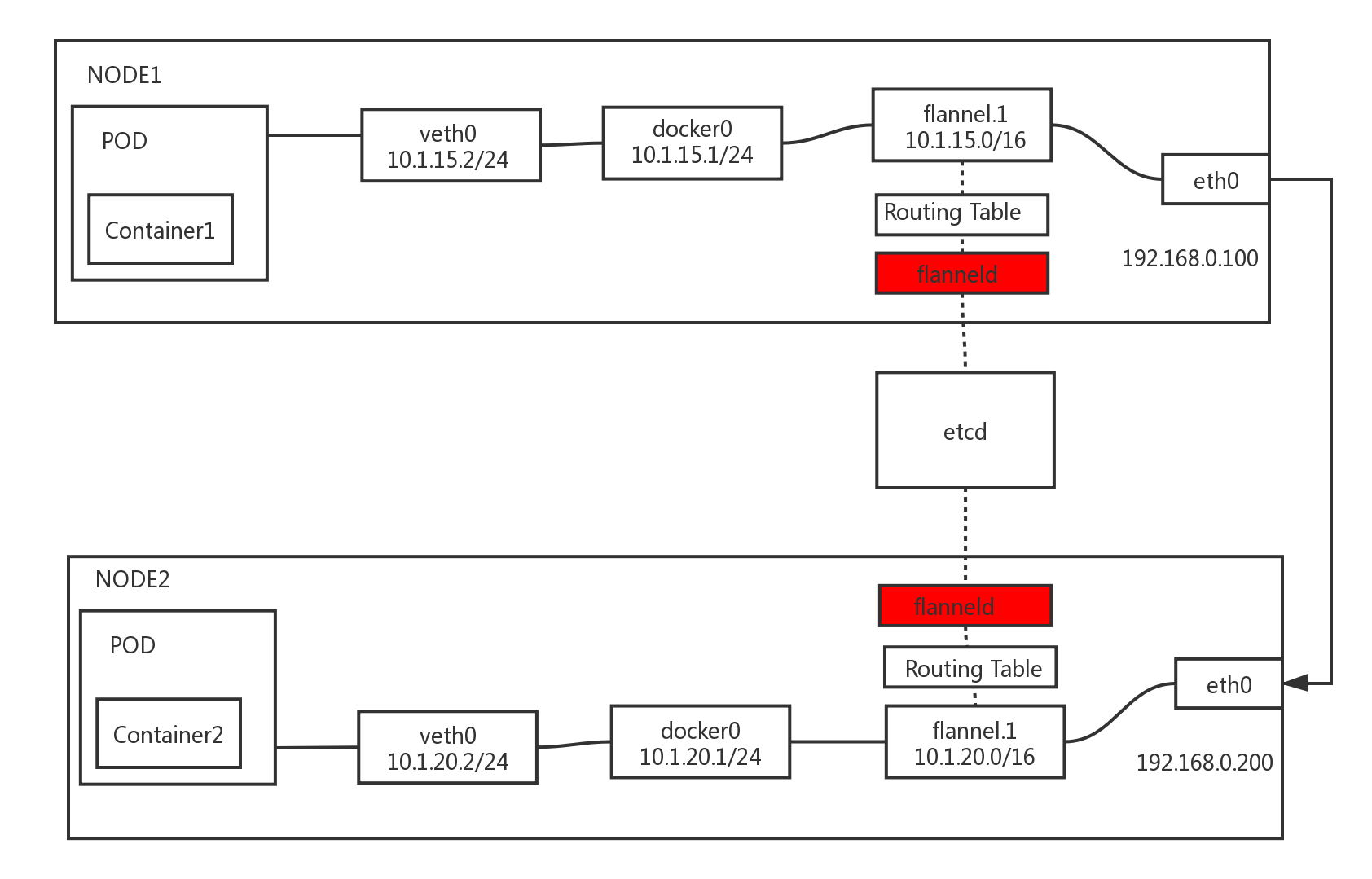
从图中可以看到,在每个 Node 节点上都运行着一个 flanneld 进程,这个进程会创建名为 flannel.1 的网桥,这个网桥一边连接着 docker0 网络接口,另一边连接着 Node 节点上的 eth0 网络接口。
flanneld 进程也需要与集群中的 etcd 数据库连接,通过 etcd 管理可分配的 IP 地址段资源(这样就实现不同 Node 上的 Pod 分配的 IP 地址不冲突),监控 etcd 中每个 Pod 的实际地址,并在内存中建立 Pod 节点路由表(Routing Table),将 docker0 的数据包包装起来,通过物理网络的连接将数据包投递到目标 flanneld,这样就完成了 Pod 之间的通信。
Flannel 底层通信协议的可选技术包括:UDP、VxLan、AWS VPC 等,默认采用的是 UDP 传输协议,由于 UDP 协议本身是非可靠协议,如果需要应用到大流量、高并发的场景下,就还需要多次测试确保没有问题。
评论区